Факторный анализ. Метод главных компонент
Исходной для анализа является матрица данных
размерности
 ,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям
,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям .
Исходные данные нормируются, для чего
вычисляются средние значения показателей
.
Исходные данные нормируются, для чего
вычисляются средние значения показателей ,
а также значения стандартных отклонений
,
а также значения стандартных отклонений .
Тогда матрица нормированных значений
.
Тогда матрица нормированных значений

с
элементами

Рассчитывается матрица парных коэффициентов корреляции:

На
главной диагонали матрицы расположены
единичные элементы
 .
.
Модель компонентного анализа строится путем представления исходных нормированных данных в виде линейной комбинации главных компонент:

где
 -
«вес», т.е. факторная нагрузка
-
«вес», т.е. факторная нагрузка -й
главной компоненты на
-й
главной компоненты на -ю
переменную;
-ю
переменную;
 -значение
-значение
 -й
главной компоненты для
-й
главной компоненты для -го
наблюдения (объекта), где
-го
наблюдения (объекта), где .
.
В матричной форме модель имеет вид

здесь
 - матрица главных компонент размерности
- матрица главных компонент размерности ,
,
 -
матрица факторных нагрузок той же
размерности.
-
матрица факторных нагрузок той же
размерности.
Матрица
 описывает
описывает наблюдений в пространстве
наблюдений в пространстве главных компонент. При этом элементы
матрицы
главных компонент. При этом элементы
матрицы нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что
нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что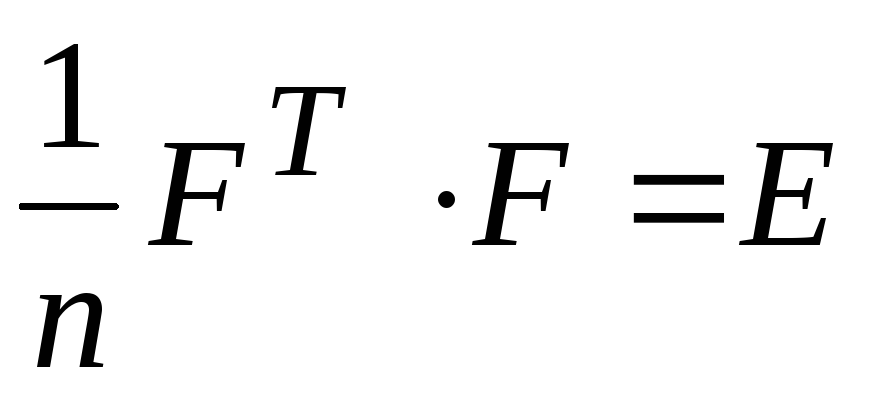 ,
где
,
где – единичная матрица размерности
– единичная матрица размерности .
.
Элемент
 матрицы
матрицы характеризует тесноту линейной связи
между исходной переменной
характеризует тесноту линейной связи
между исходной переменной и главной компонентой
и главной компонентой ,
следовательно, принимает значения
,
следовательно, принимает значения .
.
Корреляционная
матрица
 может быть выражена через матрицу
факторных нагрузок
может быть выражена через матрицу
факторных нагрузок .
.
По
главной диагонали корреляционной
матрицы располагаются единицы и по
аналогии с ковариационной матрицей они
представляют собой дисперсии используемых
 -признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы
-признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы -признаков
в выборочной совокупности объема
-признаков
в выборочной совокупности объема равна сумме этих единиц, т.е. равна следу
корреляционной матрицы
равна сумме этих единиц, т.е. равна следу
корреляционной матрицы .
.
Корреляционная матриц может быть преобразована в диагональную, то есть матрицу, все значения которой, кроме диагональных, равны нулю:
 ,
,
где
 - диагональная матрица, на главной
диагонали которой находятся собственные
числа
- диагональная матрица, на главной
диагонали которой находятся собственные
числа корреляционной матрицы,
корреляционной матрицы, - матрица, столбцы которой – собственные
вектора корреляционной матрицы
- матрица, столбцы которой – собственные
вектора корреляционной матрицы .
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения
.
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения для любых
для любых .
.
Собственные
значения
 находятся как корни характеристического
уравнения
находятся как корни характеристического
уравнения

Собственный
вектор
 ,
соответствующий собственному значению
,
соответствующий собственному значению корреляционной матрицы
корреляционной матрицы ,
определяется как отличное от нуля
решение уравнения
,
определяется как отличное от нуля
решение уравнения

Нормированный
собственный вектор
 равен
равен

Превращение
в нуль недиагональных членов означает,
что признаки становятся независимыми
друг от друга (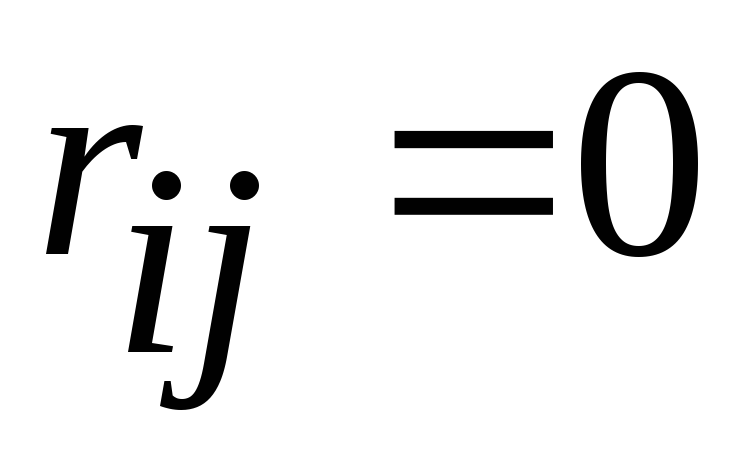 при
при ).
).
Суммарная
дисперсия всей системы
 переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений
переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений корреляционной матрицы для каждого из
корреляционной матрицы для каждого из -признаков.
Сумма этих собственных значений
-признаков.
Сумма этих собственных значений равна следу корреляционной матрицы,
т.е.
равна следу корреляционной матрицы,
т.е. ,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков
,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков в условиях, если бы признаки были бы
независимыми друг от друга.
в условиях, если бы признаки были бы
независимыми друг от друга.
В
методе главных компонент сначала по
исходным данным рассчитывается
корреляционная матрица. Затем производят
её ортогональное преобразование и
посредством этого находят факторные
нагрузки
 для всех
для всех переменных и
переменных и факторов (матрицу факторных нагрузок),
собственные значения
факторов (матрицу факторных нагрузок),
собственные значения и определяют веса факторов.
и определяют веса факторов.
Матрицу
факторных нагрузок А можно определить
как
 ,
а
,
а -й
столбец матрицы А - как
-й
столбец матрицы А - как .
.
Вес
факторов
 или
или отражает долю в общей дисперсии, вносимую
данным фактором.
отражает долю в общей дисперсии, вносимую
данным фактором.
Факторные
нагрузки изменяются от –1 до +1 и являются
аналогом коэффициентов корреляции. В
матрице факторных нагрузок необходимо
выделить значимые и незначимые нагрузки
с помощью критерия Стьюдента
 .
.
Сумма
квадратов нагрузок
 -го
фактора во всех
-го
фактора во всех -признаках
равна собственному значению данного
фактора
-признаках
равна собственному значению данного
фактора .
Тогда
.
Тогда -вклад
i-ой переменной в % в формировании j-го
фактора.
-вклад
i-ой переменной в % в формировании j-го
фактора.
Сумма
квадратов всех факторных нагрузок по
строке равна единице, полной дисперсии
одной переменной, а всех факторов по
всем переменным равна суммарной дисперсии
(т.е. следу или порядку корреляционной
матрицы, или сумме её собственных
значений)
 .
.
В
общем виде факторная структура i–го
признака представляется в форме
 ,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
 ,
,
где
 – значение j-ого фактора у t-ого
наблюдения,
– значение j-ого фактора у t-ого
наблюдения, -стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки;
-стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки; –факторная нагрузка,
–факторная нагрузка, –собственное значение, отвечающее
фактору j. Эти вычисленные значения
–собственное значение, отвечающее
фактору j. Эти вычисленные значения широко используются для графического
представления результатов факторного
анализа.
широко используются для графического
представления результатов факторного
анализа.
По
матрице факторных нагрузок может быть
восстановлена корреляционная матрица:
 .
.
Часть дисперсии переменной, объясняемая главными компонентами, называется общностью
 ,
,
где
 - номер переменной, а
- номер переменной, а -номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
-номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
Удельный
вклад
 -й
главной компоненты определяется по
формуле
-й
главной компоненты определяется по
формуле
 .
.
Суммарный
вклад учитываемых
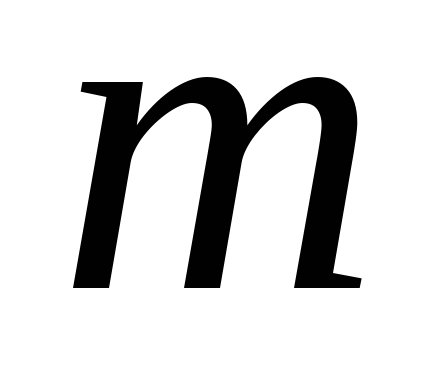 главных компонент определяется из
выражения
главных компонент определяется из
выражения
 .
.
Обычно
для анализа используют
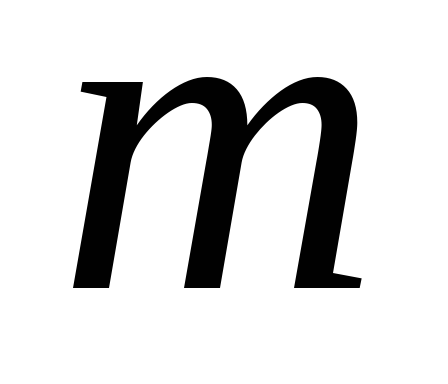 первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
Матрица факторных нагрузок А используется для интерпретации главных компонент, при этом обычно рассматриваются те значения, которые превышают 0,5.
Значения главных компонент задаются матрицей

В этой статье я бы хотел рассказать о том, как именно работает метод анализа главных компонент (PCA – principal component analysis) с точки зрения интуиции, стоящей за ее математическим аппаратом. Максимально просто, но подробно.
Математика вообще очень красивая и изящная наука, но порой ее красота скрывается за кучей слоев абстракции. Показать эту красоту лучше всего на простых примерах, которые, так сказать, можно покрутить, поиграть и пощупать, потому что в конце концов все оказывается гораздо проще, чем кажется на первый взгляд – самое главное понять и представить.
В анализе данных, как и в любом другом анализе, порой бывает нелишним создать упрощенную модель, максимально точно описывающую реальное положение дел. Часто бывает так, что признаки довольно сильно зависят друг от друга и их одновременное наличие избыточно.
К примеру, расход топлива у нас меряется в литрах на 100 км, а в США в милях на галлон. На первый взгляд, величиные разные, но на самом деле они строго зависят друг от друга. В миле 1600км, а в галлоне 3.8л. Один признак строго зависит от другого, зная один, знаем и другой.
Но гораздо чаще бывает так, что признаки зависят друг от друга не так строго и (что важно!) не так явно. Объем двигателя в целом положительно влияет на разгон до 100 км/ч, но это верно не всегда. А еще может оказаться, что с учетом не видимых на первый взгляд факторов (типа улучшения качества топлива, использования более легких материалов и прочих современных достижений), год автомобиля не сильно, но тоже влияет на его разгон.
Зная зависимости и их силу, мы можем выразить несколько признаков через один, слить воедино, так сказать, и работать уже с более простой моделью. Конечно, избежать потерь информации, скорее всего не удастся, но минимизировать ее нам поможет как раз метод PCA.
Выражаясь более строго, данный метод аппроксимирует n-размерное облако наблюдений до эллипсоида (тоже n-мерного), полуоси которого и будут являться будущими главными компонентами. И при проекции на такие оси (снижении размерности) сохраняется наибольшее количество информации.
Шаг 1. Подготовка данных
Здесь для простоты примера я не буду брать реальные обучающие датасеты на десятки признаков и сотни наблюдений, а сделаю свой, максимально простой игрушечный пример. 2 признака и 10 наблюдений будет вполне достаточно для описания того, что, а главное – зачем, происходит в недрах алгоритма.
Сгенерируем выборку:

X = np.arange(1,11) y = 2 * x + np.random.randn(10)*2 X = np.vstack((x,y)) print X OUT: [[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. ] [ 2.73446908 4.35122722 7.21132988 11.24872601 9.58103444 12.09865079 13.78706794 13.85301221 15.29003911 18.0998018 ]]
В данной выборке у нас имеются два признака, сильно коррелирующие друг с другом. С помощью алгоритма PCA мы сможем легко найти признак-комбинацию и, ценой части информации, выразить оба этих признака одним новым. Итак, давайте разбираться!
Для начала немного статистики. Вспомним, что для описания случайной величины используются моменты. Нужные нам – мат. ожидание и дисперсия. Можно сказать, что мат. ожидание – это «центр тяжести» величины, а дисперсия – это ее «размеры». Грубо говоря, мат. ожидание задает положение случайной величины, а дисперсия – ее размер.
Сам процесс проецирования на вектор никак не влияет на значения средних, так как для минимизации потерь информации наш вектор должен проходить через центр нашей выборки. Поэтому нет ничего страшного, если мы отцентрируем нашу выборку – линейно сдвинем ее так, чтобы средние значения признаков были равны 0. Это очень сильно упростит наши дальнейшие вычисления (хотя, стоит отметить, что можно обойтись и без центрирования).
Оператор, обратный сдвигу будет равен вектору изначальных средних значений – он понадобится для восстановления выборки в исходной размерности.

Xcentered = (X - x.mean(), X - y.mean()) m = (x.mean(), y.mean()) print Xcentered print "Mean vector: ", m OUT: (array([-4.5, -3.5, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5, 4.5]), array([-8.44644233, -8.32845585, -4.93314426, -2.56723136, 1.01013247, 0.58413394, 1.86599939, 7.00558491, 4.21440647, 9.59501658])) Mean vector: (5.5, 10.314393916)
Дисперсия же сильно зависит от порядков значений случайной величины, т.е. чувствительна к масштабированию. Поэтому если единицы измерения признаков сильно различаются своими порядками, крайне рекомендуется стандартизировать их. В нашем случае значения не сильно разнятся в порядках, так что для простоты примера мы не будем выполнять эту операцию.
Шаг 2. Ковариационная матрица
В случае с многомерной случайной величиной (случайным вектором) положение центра все так же будет являться мат. ожиданиями ее проекций на оси. А вот для описания ее формы уже недостаточно толькое ее дисперсий по осям. Посмотрите на эти графики, у всех трех случайных величин одинаковые мат.ожидания и дисперсии, а их проекции на оси в целом окажутся одинаковы!

Для описания формы случайного вектора необходима ковариационная матрица.
Это матрица, у которой (i,j) -элемент является корреляцией признаков (X i , X j). Вспомним формулу ковариации:
В нашем случае она упрощается, так как E(X i) = E(X j) = 0:
Заметим, что когда X i = X j:
и это справедливо для любых случайных величин.
Таким образом, в нашей матрице по диагонали будут дисперсии признаков (т.к. i = j), а в остальных ячейках – ковариации соответствующих пар признаков. А в силу симметричности ковариации матрица тоже будет симметрична.
Замечание: Ковариационная матрица является обобщением дисперсии на случай многомерных случайных величин – она так же описывает форму (разброс) случайной величины, как и дисперсия.
И действительно, дисперсия одномерной случайной величины – это ковариационная матрица размера 1x1, в которой ее единственный член задан формулой Cov(X,X) = Var(X).
Итак, сформируем ковариационную матрицу Σ
для нашей выборки. Для этого посчитаем дисперсии X i и X j , а также их ковариацию. Можно воспользоваться вышенаписанной формулой, но раз уж мы вооружились Python’ом, то грех не воспользоваться функцией numpy.cov(X)
. Она принимает на вход список всех признаков случайной величины и возвращает ее ковариационную матрицу и где X – n-мерный случайный вектор (n-количество строк). Функция отлично подходит и для расчета несмещенной дисперсии, и для ковариации двух величин, и для составления ковариационной матрицы.
(Напомню, что в Python матрица представляется массивом-столбцом массивов-строк.)
Covmat = np.cov(Xcentered) print covmat, "n" print "Variance of X: ", np.cov(Xcentered) print "Variance of Y: ", np.cov(Xcentered) print "Covariance X and Y: ", np.cov(Xcentered) OUT: [[ 9.16666667 17.93002811] [ 17.93002811 37.26438587]] Variance of X: 9.16666666667 Variance of Y: 37.2643858743 Covariance X and Y: 17.9300281124
Шаг 3. Собственные вектора и значения (айгенпары)
О"кей, мы получили матрицу, описывающую форму нашей случайной величины, из которой мы можем получить ее размеры по x и y (т.е. X 1 и X 2), а также примерную форму на плоскости. Теперь надо надо найти такой вектор (в нашем случае только один), при котором максимизировался бы размер (дисперсия) проекции нашей выборки на него.
Замечание: Обобщение дисперсии на высшие размерности - ковариационная матрица, и эти два понятия эквивалентны. При проекции на вектор максимизируется дисперсия проекции, при проекции на пространства больших порядков – вся ее ковариационная матрица.
Итак, возьмем единичный вектор на который будем проецировать наш случайный вектор X. Тогда проекция на него будет равна v T X. Дисперсия проекции на вектор будет соответственно равна Var(v T X). В общем виде в векторной форме (для центрированных величин) дисперсия выражается так:
Соответственно, дисперсия проекции:
Легко заметить, что дисперсия максимизируется при максимальном значении v T Σv. Здесь нам поможет отношение Рэлея. Не вдаваясь слишком глубоко в математику, просто скажу, что у отношения Рэлея есть специальный случай для ковариационных матриц:
Последняя формула должна быть знакома по теме разложения матрицы на собственные вектора и значения. x является собственным вектором, а λ – собственным значением. Количество собственных векторов и значений равны размеру матрицы (и значения могут повторяться).
Кстати, в английском языке собственные значения и векторы именуются eigenvalues и eigenvectors соответственно.
Мне кажется, это звучит намного более красиво (и кратко), чем наши термины.
Таким образом, направление максимальной дисперсии у проекции всегда совпадает с айгенвектором имеющим максимальное собственное значение, равное величине этой дисперсии .
И это справедливо также для проекций на большее количество измерений – дисперсия (ковариационная матрица) проекции на m-мерное пространство будет максимальна в направлении m айгенвекторов, имеющих максимальные собственные значения.
Размерность нашей выборки равна двум и количество айгенвекторов у нее, соответственно, 2. Найдем их.
В библиотеке numpy реализована функция numpy.linalg.eig(X) , где X – квадратная матрица. Она возвращает 2 массива – массив айгензначений и массив айгенвекторов (векторы-столбцы). И векторы нормированы - их длина равна 1. Как раз то, что надо. Эти 2 вектора задают новый базис для выборки, такой что его оси совпадают с полуосями аппроксимирующего эллипса нашей выборки.

На этом графике мы апроксимировали нашу выборку эллипсом с радиусами в 2 сигмы (т.е. он должен содержать в себе 95% всех наблюдений – что в принципе мы здесь и наблюдаем). Я инвертировал больший вектор (функция eig(X) направляла его в обратную сторону) – нам важно направление, а не ориентация вектора.
Шаг 4. Снижение размерности (проекция)
Наибольший вектор имеет направление, схожее с линией регрессии и спроецировав на него нашу выборку мы потеряем информацию, сравнимую с суммой остаточных членов регрессии (только расстояние теперь евклидово, а не дельта по Y). В нашем случае зависимость между признаками очень сильная, так что потеря информации будет минимальна. «Цена» проекции - дисперсия по меньшему айгенвектору - как видно из предыдущего графика, очень невелика.
Замечание: диагональные элементы ковариационной матрицы показывают дисперсии по изначальному базису, а ее собственные значения – по новому (по главным компонентам).
Часто требуется оценить объем потерянной (и сохраненной) информации. Удобнее всего представить в процентах. Мы берем дисперсии по каждой из осей и делим на общую сумму дисперсий по осям (т.е. сумму всех собственных чисел ковариационной матрицы).
Таким образом, наш больший вектор описывает 45.994 / 46.431 * 100% = 99.06%, а меньший, соответственно, примерно 0.94%. Отбросив меньший вектор и спроецировав данные на больший, мы потеряем меньше 1% информации! Отличный результат!
Замечание: На практике, в большинстве случаев, если суммарная потеря информации составляет не более 10-20%, то можно спокойно снижать размерность.
Для проведения проекции, как уже упоминалось ранее на шаге 3, надо провести операцию v T X (вектор должен быть длины 1). Или, если у нас не один вектор, а гиперплоскость, то вместо вектора v T берем матрицу базисных векторов V T . Полученный вектор (или матрица) будет являться массивом проекций наших наблюдений.
V = (-vecs, -vecs) Xnew = dot(v,Xcentered) print Xnew OUT: [ -9.56404107 -9.02021624 -5.52974822 -2.96481262 0.68933859 0.74406645 2.33433492 7.39307974 5.3212742 10.59672425]
dot(X,Y) - почленное произведение (так мы перемножаем векторы и матрицы в Python)
Нетрудно заметить, что значения проекций соответствуют картине на предыдущем графике.
Шаг 5. Восстановление данных
С проекцией удобно работать, строить на ее основе гипотезы и разрабатывать модели. Но не всегда полученные главные компоненты будут иметь явный, понятный постороннему человеку, смысл. Иногда полезно раскодировать, к примеру, обнаруженные выбросы, чтобы посмотреть, что за наблюдения за ними стоят.
Это очень просто. У нас есть вся необходимая информация, а именно координаты базисных векторов в исходном базисе (векторы, на которые мы проецировали) и вектор средних (для отмены центровки). Возьмем, к примеру, наибольшее значение: 10.596… и раскодируем его. Для этого умножим его справа на транспонированный вектор и прибавим вектор средних, или в общем виде для всей выбоки: X T v T +m
Xrestored = dot(Xnew,v) + m print "Restored: ", Xrestored print "Original: ", X[:,9] OUT: Restored: [ 10.13864361 19.84190935] Original: [ 10. 19.9094105]
Разница небольшая, но она есть. Ведь потерянная информация не восстанавливается. Тем не менее, если простота важнее точности, восстановленное значение отлично аппроксимирует исходное.
Вместо заключения – проверка алгоритма
Итак, мы разобрали алгоритм, показали как он работает на игрушечном примере, теперь осталось только сравнить его с PCA, реализованным в sklearn – ведь пользоваться будем именно им.
From sklearn.decomposition import PCA pca = PCA(n_components = 1) XPCAreduced = pca.fit_transform(transpose(X))
Параметр n_components указывает на количество измерений, на которые будет производиться проекция, то есть до скольки измерений мы хотим снизить наш датасет. Другими словами – это n айгенвекторов с самыми большими собственными числами. Проверим результат снижения размерности:
Print "Our reduced X: n", Xnew print "Sklearn reduced X: n", XPCAreduced OUT: Our reduced X: [ -9.56404106 -9.02021625 -5.52974822 -2.96481262 0.68933859 0.74406645 2.33433492 7.39307974 5.3212742 10.59672425] Sklearn reduced X: [[ -9.56404106] [ -9.02021625] [ -5.52974822] [ -2.96481262] [ 0.68933859] [ 0.74406645] [ 2.33433492] [ 7.39307974] [ 5.3212742 ] [ 10.59672425]]
Мы возвращали результат как матрицу вектор-столбцов наблюдений (это более канонический вид с точки зрения линейной алгебры), PCA в sklearn же возвращает вертикальный массив.
В принципе, это не критично, просто стоит отметить, что в линейной алгебре канонично записывать матрицы через вектор-столбцы, а в анализе данных (и прочих связанных с БД областях) наблюдения (транзакции, записи) обычно записываются строками.
Проверим и прочие параметры модели – функция имеет ряд атрибутов, позволяющих получить доступ к промежуточным переменным:
Вектор средних: mean_
- Вектор(матрица) проекции: components_
- Дисперсии осей проекции (выборочная): explained_variance_
- Доля информации (доля от общей дисперсии): explained_variance_ratio_
Замечание: explained_variance_ показывает выборочную дисперсию, тогда как функция cov() для построения ковариационной матрицы рассчитывает несмещенные дисперсии!
Сравним полученные нами значения со значениями библиотечной функции.
Print "Mean vector: ", pca.mean_, m print "Projection: ", pca.components_, v print "Explained variance ratio: ", pca.explained_variance_ratio_, l/sum(l) OUT: Mean vector: [ 5.5 10.31439392] (5.5, 10.314393916) Projection: [[ 0.43774316 0.89910006]] (0.43774316434772387, 0.89910006232167594) Explained variance: [ 41.39455058] 45.9939450918 Explained variance ratio: [ 0.99058588] 0.990585881238
Единственное различие – в дисперсиях, но как уже упоминалось, мы использовали функцию cov(), которая использует несмещенную дисперсию, тогда как атрибут explained_variance_ возвращает выборочную. Они отличаются только тем, что первая для получения мат.ожидания делит на (n-1), а вторая – на n. Легко проверить, что 45.99 ∙ (10 - 1) / 10 = 41.39.
Все остальные значения совпадают, что означает, что наши алгоритмы эквивалентны. И напоследок замечу, что атрибуты библиотечного алгоритма имеют меньшую точность, поскольку он наверняка оптимизирован под быстродействие, либо просто для удобства округляет значения (либо у меня какие-то глюки).
Замечание: библиотечный метод автоматически проецирует на оси, максимизирующие дисперсию. Это не всегда рационально. К примеру, на данном рисунке неаккуратное снижение размерности приведет к тому, что классификация станет невозможна. Тем не менее, проекция на меньший вектор успешно снизит размерность и сохранит классификатор.

Итак, мы рассмотрели принципы работы алгоритма PCA и его реализации в sklearn. Я надеюсь, эта статья была достаточно понятна тем, кто только начинает знакомство с анализом данных, а также хоть немного информативна для тех, кто хорошо знает данный алгоритм. Интуитивное представление крайне полезно для понимания того как работает метод, а понимание очень важно для правильной настройки выбранной модели. Спасибо за внимание!
P.S.: Просьба не ругать автора за возможные неточности. Автор сам в процессе знакомства с дата-анализом и хочет помочь таким же как он в процессе освоения этой удивительной области знаний! Но конструктивная критика и разнообразный опыт всячески приветствуются!
Компонентный анализ относится к многомерным методам снижения размерности. Он содержит один метод - метод главных компонент. Главные компоненты представляют собой ортогональную систему координат, в которой дисперсии компонент характеризуют их статистические свойства.
Учитывая, что объекты исследования в экономике характеризуются большим, но конечным количеством признаков, влияние которых подвергается воздействию большого количества случайных причин.
Вычисление главных компонент
Первой главной компонентой Z1 исследуемой системы признаков Х1, Х2, Х3 , Х4 ,…, Хn называется такая центрировано - нормированная линейная комбинация этих признаков, которая среди прочих центрировано - нормированных линейных комбинаций этих признаков, имеет дисперсию наиболее изменчивую.
В качестве второй главной компоненты Z2 мы будем брать такую центрировано - нормированную комбинацию этих признаков, которая:
не коррелированна с первой главной компонентой,
не коррелированны с первой главной компонентой, эта комбинация имеет наибольшую дисперсию.
K-ой главной компонентой Zk (k=1…m) мы будем называть такую центрировано - нормированную комбинацию признаков, которая:
не коррелированна с к-1 предыдущими главными компонентами,
среди всех возможных комбинаций исходных признаков, которые не
не коррелированны с к-1 предыдущими главными компонентами, эта комбинация имеет наибольшую дисперсию.
Введём ортогональную матрицу U и перейдём от переменных Х к переменным Z, причём
Вектор выбирается т. о., чтобы дисперсия была максимальной. После получения выбирается т. о., чтобы дисперсия была максимальной при условии, что не коррелированно с и т. д.
Так как признаки измерены в несопоставимых величинах, то удобнее будет перейти к центрированно-нормированным величинам. Матрицу исходных центрированно-нормированных значений признаков найдем из соотношения:

где - несмещенная, состоятельная и эффективная оценка математического ожидания,
Несмещенная, состоятельная и эффективная оценка дисперсии.
Матрица наблюденных значений исходных признаков приведена в Приложении.
Центрирование и нормирование произведено с помощью программы"Stadia".
Так как признаки центрированы и нормированы, то оценку корреляционной матрицы можно произвести по формуле:

Перед тем как проводить компонентный анализ, проведем анализ независимости исходных признаков.
Проверка значимости матрицы парных корреляций с помощью критерия Уилкса.
Выдвигаем гипотезу:
Н0: незначима
Н1: значима
125,7; (0,05;3,3) = 7,8
т.к > , то гипотеза Н0 отвергается и матрица является значимой, следовательно, имеет смысл проводить компонентный анализ.
Проверим гипотезу о диагональности ковариационной матрицы
Выдвигаем гипотезу:
Строим статистику, распределена по закону с степенями свободы.
123,21, (0,05;10) =18,307
т.к >, то гипотеза Н0 отвергается и имеет смысл проводить компонентный анализ.
Для построения матрицы факторных нагрузок необходимо найти собственные числа матрицы, решив уравнение.
Используем для этой операции функцию eigenvals системы MathCAD, которая возвращает собственные числа матрицы:
Т.к. исходные данные представляют собой выборку из генеральной совокупности, то мы получили не собственные числа и собственные вектора матрицы, а их оценки. Нас будет интересовать на сколько “хорошо” со статистической точки зрения выборочные характеристики описывают соответствующие параметры для генеральной совокупности.
Доверительный интервал для i-го собственного числа ищется по формуле:

Доверительные интервалы для собственных чисел в итоге принимают вид:

Оценка значения нескольких собственных чисел попадает в доверительный интервал других собственных чисел. Необходимо проверить гипотезу о кратности собственных чисел.
Проверка кратности производится с помощью статистики
где r-количество кратных корней.
Данная статистика в случае справедливости распределена по закону с числом степеней свободы. Выдвинем гипотезы:
Так как, то гипотеза отвергается, то есть собственные числа и не кратны.
Так как, то гипотеза отвергается, то есть собственные числа и не кратны.
Необходимо выделить главные компоненты на уровне информативности 0,85. Мера информативности показывает какую часть или какую долю дисперсии исходных признаков составляют k-первых главных компонент. Мерой информативности будем называть величину:
На заданном уровне информативности выделено три главных компоненты.
Запишем матрицу =

Для получения нормализованного вектора перехода от исходных признаков к главным компонентам необходимо решить систему уравнений: , где - соответствующее собственное число. После получения решения системы необходимо затем нормировать полученный вектор.
Для решения данной задачи воспользуемся функцией eigenvec системы MathCAD, которая возвращает нормированный вектор для соответствующего собственного числа.
В нашем случае первых четырех главных компонент достаточно для достижения заданного уровня информативности, поэтому матрица U (матрица перехода от исходного базиса к базису из собственных векторов)
Строим матрицу U, столбцами которой являются собственные вектора:

Матрица весовых коэффициентов:


Коэффициенты матрицы А являются коэффициентами корреляции между центрировано - нормированными исходными признаками и ненормированными главными компонентами, и показывают наличие, силу и направление линейной связи между соответствующими исходными признаками и соответствующими главными компонентами.
Метод главных компонент – это метод, который переводит большое количество связанных между собой (зависимых, коррелирующих) переменных в меньшее количество независимых переменных, так как большое количество переменных часто затрудняет анализ и интерпретацию информации. Строго говоря, этот метод не относится к факторному анализу, хотя и имеет с ним много общего. Специфическим является, во-первых, то, что в ходе вычислительных процедур одновременно получают все главные компоненты и их число первоначально равно числу исходных переменных; во-вторых, постулируется возможность полного разложения дисперсии всех исходных переменных, т.е. ее полное объяснение через латентные факторы (обобщенные признаки).
Например, представим, что мы провели исследование, в котором измерили у студентов интеллект по тесту Векслера, тесту Айзенка, тесту Равена, а также успеваемость по социальной, когнитивной и общей психологии. Вполне возможно, что показатели различных тестов на интеллект будут коррелировать между собой, так как они, в конце концов, измеряют одну характеристику испытуемого – его интеллектуальные способности, хотя и по-разному. Если переменных в исследовании слишком много (x 1 , x 2 , …, x p ) , а некоторые из них взаимосвязаны, то у исследователя иногда возникает желание уменьшить сложность данных, сократив количество переменных. Для этого и служит метод главных компонент, который создает несколько новых переменных y 1 , y 2 , …, y p , каждая из которых является линейной комбинацией первоначальных переменных x 1 , x 2 , …, x p :
y 1 =a 11 x 1 +a 12 x 2 +…+a 1p x p
y 2 =a 21 x 1 +a 22 x 2 +…+a 2p x p
… (1)
y p =a p1 x 1 +a p2 x 2 +…+a pp x p
Переменные y 1 , y 2 , …, y p называются главными компонентами или факторами. Таким образом, фактор – это искусственный статистический показатель, возникающий в результате специальных преобразований корреляционной матрицы . Процедура извлечения факторов называется факторизацией матрицы. В результате факторизации из корреляционной матрицы может быть извлечено разное количество факторов вплоть до числа, равного количеству исходных переменных. Однако факторы, определяемые в результате факторизации, как правило, не равноценны по своему значению.
Коэффициенты a ij , определяющие новую переменную, выбираются таким образом, чтобы новые переменные (главные компоненты, факторы) описывали максимальное количество вариативности данных и не коррелировали между собой. Часто полезно представить коэффициенты a ij таким образом, чтобы они представляли собой коэффициент корреляции между исходной переменной и новой переменной (фактором). Это достигается умножением a ij на стандартное отклонение фактора. В большинстве статистических пакетов так и делается (в программе STATISTICA тоже). Коэффициенты a ij Обычно они представляются в виде таблицы, где факторы располагаются в виде столбцов, а переменные в виде строк:
Такая таблица называется таблицей (матрицей) факторных нагрузок. Числа, приведенные в ней, являются коэффициентами a ij .Число 0,86 означает, что корреляция между первым фактором и значением по тесту Векслера равна 0,86. Чем выше факторная нагрузка по абсолютной величине, тем сильнее связь переменной с фактором.
Метод главных компонент
Метод главных компонент (англ. Principal component analysis, PCA ) - один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации . Изобретен К. Пирсоном (англ. Karl Pearson ) в г. Применяется во многих областях, таких как распознавание образов , компьютерное зрение , сжатие данных и т. п. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных. Иногда метод главных компонент называют преобразованием Кархунена-Лоэва (англ. Karhunen-Loeve ) или преобразованием Хотеллинга (англ. Hotelling transform ). Другие способы уменьшения размерности данных - это метод независимых компонент, многомерное шкалирование, а также многочисленные нелинейные обобщения: метод главных кривых и многообразий, метод упругих карт , поиск наилучшей проекции (англ. Projection Pursuit ), нейросетевые методы «узкого горла », и др.
Формальная постановка задачи
Задача анализа главных компонент, имеет, как минимум, четыре базовых версии:
- аппроксимировать данные линейными многообразиями меньшей размерности;
- найти подпространства меньшей размерности, в ортогональной проекции на которые разброс данных (то есть среднеквадратичное отклонение от среднего значения) максимален;
- найти подпространства меньшей размерности, в ортогональной проекции на которые среднеквадратичное расстояние между точками максимально;
- для данной многомерной случайной величины построить такое ортогональное преобразование координат, что в результате корреляции между отдельными координатами обратятся в ноль.
Первые три версии оперируют конечными множествами данных. Они эквивалентны и не используют никакой гипотезы о статистическом порождении данных. Четвёртая версия оперирует случайными величинами. Конечные множества появляются здесь как выборки из данного распределения, а решение трёх первых задач - как приближение к «истинному» преобразованию Кархунена-Лоэва. При этом возникает дополнительный и не вполне тривиальный вопрос о точности этого приближения.
Аппроксимация данных линейными многообразиями
Иллюстрация к знаменитой работе К. Пирсона (1901): даны точки на плоскости, - расстояние от до прямой . Ищется прямая , минимизирующая сумму
Метод главных компонент начинался с задачи наилучшей аппроксимации конечного множества точек прямыми и плоскостями (К. Пирсон, 1901). Дано конечное множество векторов . Для каждого среди всех -мерных линейных многообразий в найти такое , что сумма квадратов уклонений от минимальна:
,где - евклидово расстояние от точки до линейного многообразия. Всякое -мерное линейное многообразие в может быть задано как множество линейных комбинаций , где параметры пробегают вещественную прямую , а - ортонормированный набор векторов
,где евклидова норма, - евклидово скалярное произведение, или в координатной форме:
.Решение задачи аппроксимации для даётся набором вложенных линейных многообразий , . Эти линейные многообразия определяются ортонормированным набором векторов (векторами главных компонент) и вектором . Вектор ищется, как решение задачи минимизации для :
.Векторы главных компонент могут быть найдены как решения однотипных задач оптимизации :
1) централизуем данные (вычитаем среднее): . Теперь ; 2) находим первую главную компоненту как решение задачи; . Если решение не единственно, то выбираем одно из них. 3) Вычитаем из данных проекцию на первую главную компоненту: ; 4) находим вторую главную компоненту как решение задачи . Если решение не единственно, то выбираем одно из них. … 2k-1) Вычитаем проекцию на -ю главную компоненту (напомним, что проекции на предшествующие главные компоненты уже вычтены): ; 2k) находим k-ю главную компоненту как решение задачи: . Если решение не единственно, то выбираем одно из них. …
На каждом подготовительном шаге вычитаем проекцию на предшествующую главную компоненту. Найденные векторы ортонормированы просто в результате решения описанной задачи оптимизации, однако чтобы не дать ошибкам вычисления нарушить взаимную ортогональность векторов главных компонент, можно включать в условия задачи оптимизации.
Неединственность в определении помимо тривиального произвола в выборе знака ( и решают ту же задачу) может быть более существенной и происходить, например, из условий симметрии данных. Последняя главная компонента - единичный вектор, ортогональный всем предыдущим .
Поиск ортогональных проекций с наибольшим рассеянием

Первая главная компонента максимизирует выборочную дисперсию проекции данных
Пусть нам дан центрированный набор векторов данных (среднее арифметическое значение равно нулю). Задача - найти такое ортогональное преобразование в новую систему координат , для которого были бы верны следующие условия:
Теория сингулярного разложения была создана Дж. Дж. Сильвестром (англ. James Joseph Sylvester ) в г. и изложена во всех подробных руководствах по теории матриц .
Простой итерационный алгоритм сингулярного разложения
Основная процедура - поиск наилучшего приближения произвольной матрицы матрицей вида (где - -мерный вектор, а - -мерный вектор) методом наименьших квадратов:
Решение этой задачи дается последовательными итерациями по явным формулам. При фиксированном векторе значения , доставляющие минимум форме , однозначно и явно определяются из равенств :
Аналогично, при фиксированном векторе определяются значения :
B качестве начального приближения вектора возьмем случайный вектор единичной длины, вычисляем вектор , далее для этого вектора вычисляем вектор и т. д. Каждый шаг уменьшает значение . В качестве критерия остановки используется малость относительного уменьшения значения минимизируемого функционала за шаг итерации () или малость самого значения .
В результате для матрицы получили наилучшее приближение матрицей вида (здесь верхним индексом обозначен номер приближения). Далее, из матрицы вычитаем полученную матрицу , и для полученной матрицы уклонений вновь ищем наилучшее приближение этого же вида и т. д., пока, например, норма не станет достаточно малой. В результате получили итерационную процедуру разложения матрицы в виде суммы матриц ранга 1, то есть . Полагаем и нормируем векторы : В результате получена аппроксимация сингулярных чисел и сингулярных векторов (правых - и левых - ).
К достоинствам этого алгоритма относится его исключительная простота и возможность почти без изменений перенести его на данные с пробелами , а также взвешенные данные.
Существуют различные модификации базового алгоритма, улучшающие точность и устойчивость. Например, векторы главных компонент при разных должны быть ортогональны «по построению», однако при большом числе итерации (большая размерность, много компонент) малые отклонения от ортогональности накапливаются и может потребоваться специальная коррекция на каждом шаге, обеспечивающая его ортогональность ранее найденным главным компонентам.
Сингулярное разложение тензоров и тензорный метод главных компонент
Часто вектор данных имеет дополнительную структуру прямоугольной таблицы (например, плоское изображение) или даже многомерной таблицы - то есть тензора : , . В этом случае также эффективно применять сингулярное разложение. Определение, основные формулы и алгоритмы переносятся практически без изменений: вместо матрицы данных имеем -индексную величину , где первый индекс -номер точки (тензора) данных.
Основная процедура - поиск наилучшего приближения тензора тензором вида (где - -мерный вектор ( - число точек данных), - вектор размерности при ) методом наименьших квадратов:
Решение этой задачи дается последовательными итерациями по явным формулам. Если заданы все векторы-сомножители кроме одного , то этот оставшийся определяется явно из достаточных условий минимума.
B качестве начального приближения векторов () возьмем случайные векторы единичной длины, вычислим вектор , далее для этого вектора и данных векторов вычисляем вектор и т. д. (циклически перебирая индексы) Каждый шаг уменьшает значение . Алгоритм, очевидно, сходится. В качестве критерия остановки используется малость относительного уменьшения значения минимизируемого функционала за цикл или малость самого значения . Далее, из тензора вычитаем полученное приближение и для остатка вновь ищем наилучшее приближение этого же вида и т. д., пока, например, норма очередного остатка не станет достаточно малой.
Это многокомпонентное сингулярное разложение (тензорный метод главных компонент) успешно применяется при обработке изображений, видеосигналов, и, шире, любых данных, имеющих табличную или тензорную структуру.
Матрица преобразования к главным компонентам
Матрица преобразования данных к главным компонентам состоит из векторов главных компонент, расположенных в порядке убывания собственных значений:
( означает транспонирование),То есть, матрица является ортогональной .
Большая часть вариации данных будет сосредоточена в первых координатах, что позволяет перейти к пространству меньшей размерности.
Остаточная дисперсия
Пусть данные центрированы, . При замене векторов данных на их проекцию на первые главных компонент вносится средний квадрат ошибки в расчете на один вектор данных:
где собственные значения эмпирической ковариационной матрицы , расположенные в порядке убывания, с учетом кратности.
Эта величина называется остаточной дисперсией . Величина
называется объяснённой дисперсией . Их сумма равна выборочной дисперсии. Соответствующий квадрат относительной ошибки - это отношение остаточной дисперсии к выборочной дисперсии (то есть доля необъяснённой дисперсии ):
По относительной ошибке оценивается применимость метода главных компонент с проецированием на первые компонент.
Замечание : в большинстве вычислительных алгоритмов собственные числа с соответствующими собственными векторами - главными компонентами вычисляются в порядке «от больших - к меньшим». Для вычисления достаточно вычислить первые собственных чисел и след эмпирической ковариационной матрицы , (сумму диагональных элементов , то есть дисперсий по осям). Тогда
Отбор главных компонент по правилу Кайзера
Целевой подход к оценке числа главных компонент по необходимой доле объяснённой дисперсии формально применим всегда, однако неявно он предполагает, что нет разделения на «сигнал» и «шум», и любая заранее заданная точность имеет смысл. Поэтому часто более продуктивна иная эвристика, основывающаяся на гипотезе о наличии «сигнала» (сравнительно малая размерность, относительно большая амплитуда) и «шума» (большая размерность, относительно малая амплитуда). С этой точки зрения метод главных компонент работает как фильтр: сигнал содержится, в основном, в проекции на первые главные компоненты, а в остальных компонентах пропорция шума намного выше.
Вопрос: как оценить число необходимых главных компонент, если отношение «сигнал/шум» заранее неизвестно?
Простейший и старейший метод отбора главных компонент даёт правило Кайзера (англ. Kaiser"s rule ): значимы те главные компоненты, для которых
то есть превосходит среднее значение (среднюю выборочную дисперсию координат вектора данных). Правило Кайзера хорошо работает в простых случаях, когда есть несколько главных компонент с , намного превосходящими среднее значение, а остальные собственные числа меньше него. В более сложных случаях оно может давать слишком много значимых главных компонент. Если данные нормированы на единичную выборочную дисперсию по осям, то правило Кайзера приобретает особо простой вид: значимы только те главные компоненты, для которых
Оценка числа главных компонент по правилу сломанной трости

Пример: оценка числа главных компонент по правилу сломанной трости в размерности 5.
Одним из наиболее популярных эвристических подходов к оценке числа необходимых главных компонент является правило сломанной трости (англ. Broken stick model ) . Набор нормированных на единичную сумму собственных чисел (, ) сравнивается с распределением длин обломков трости единичной длины, сломанной в -й случайно выбранной точке (точки разлома выбираются независимо и равнораспределены по длине трости). Пусть () - длины полученных кусков трости, занумерованные в порядке убывания длины: . Нетрудно найти математическое ожидание :
По правилу сломанной трости -й собственный вектор (в порядке убывания собственных чисел ) сохраняется в списке главных компонент, если
На Рис. приведён пример для 5-мерного случая:
=(1+1/2+1/3+1/4+1/5)/5; =(1/2+1/3+1/4+1/5)/5; =(1/3+1/4+1/5)/5; =(1/4+1/5)/5; =(1/5)/5.Для примера выбрано
=0.5; =0.3; =0.1; =0.06; =0.04.По правилу сломанной трости в этом примере следует оставлять 2 главных компоненты:
По оценкам пользователей, правило сломанной трости имеет тенденцию занижать количество значимых главных компонент.
Нормировка
Нормировка после приведения к главным компонентам
После проецирования на первые главных компонент с удобно произвести нормировку на единичную (выборочную) дисперсию по осям. Дисперсия вдоль й главной компоненты равна ), поэтому для нормировки надо разделить соответствующую координату на . Это преобразование не является ортогональным и не сохраняет скалярного произведения. Ковариационная матрица проекции данных после нормировки становится единичной, проекции на любые два ортогональных направления становятся независимыми величинами, а любой ортонормированный базис становится базисом главных компонент (напомним, что нормировка меняет отношение ортогональности векторов). Отображение из пространства исходных данных на первые главных компонент вместе с нормировкой задается матрицей
.Именно это преобразование чаще всего называется преобразованием Кархунена-Лоэва. Здесь - векторы-столбцы, а верхний индекс означает транспонирование.
Нормировка до вычисления главных компонент
Предупреждение : не следует путать нормировку, проводимую после преобразования к главным компонентам, с нормировкой и «обезразмериванием» при предобработке данных , проводимой до вычисления главных компонент. Предварительная нормировка нужна для обоснованного выбора метрики, в которой будет вычисляться наилучшая аппроксимация данных, или будут искаться направления наибольшего разброса (что эквивалентно). Например, если данные представляют собой трёхмерные векторы из «метров, литров и килограмм», то при использовании стандартного евклидового расстояния разница в 1 метр по первой координате будет вносить тот же вклад, что разница в 1 литр по второй, или в 1 кг по третьей. Обычно системы единиц, в которых представлены исходные данные, недостаточно точно отображают наши представления о естественных масштабах по осям, и проводится «обезразмеривание»: каждая координата делится на некоторый масштаб, определяемый данными, целями их обработки и процессами измерения и сбора данных.
Есть три cущественно различных стандартных подхода к такой нормировке: на единичную дисперсию по осям (масштабы по осям равны средним квадратичным уклонениям - после этого преобразования ковариационная матрица совпадает с матрицей коэффициентов корреляции), на равную точность измерения (масштаб по оси пропорционален точности измерения данной величины) и на равные требования в задаче (масштаб по оси определяется требуемой точностью прогноза данной величины или допустимым её искажением - уровнем толерантности). На выбор предобработки влияют содержательная постановка задачи, а также условия сбора данных (например, если коллекция данных принципиально не завершена и данные будут ещё поступать, то нерационально выбирать нормировку строго на единичную дисперсию, даже если это соответствует смыслу задачи, поскольку это предполагает перенормировку всех данных после получения новой порции; разумнее выбрать некоторый масштаб, грубо оценивающий стандартное отклонение, и далее его не менять).
Предварительная нормировка на единичную дисперсию по осям разрушается поворотом системы координат, если оси не являются главными компонентами, и нормировка при предобработке данных не заменяет нормировку после приведения к главным компонентам.
Механическая аналогия и метод главных компонент для взвешенных данных
Если сопоставить каждому вектору данных единичную массу, то эмпирическая ковариационная матрица совпадёт с тензором инерции этой системы точечных масс (делённым на полную массу ), а задача о главных компонентых - с задачей приведения тензора инерции к главным осям. Можно использовать дополнительную свободу в выборе значений масс для учета важности точек данных или надежности их значений (важным данным или данным из более надежных источников приписываются бо́льшие массы). Если вектору данных придаётся масса , то вместо эмпирической ковариационной матрицы получим
Все дальнейшие операции по приведению к главным компонентам производятся так же, как и в основной версии метода: ищем ортонормированный собственный базис , упорядочиваем его по убыванию собственных значений, оцениваем средневзвешенную ошибку аппроксимации данных первыми компонентами (по суммам собственных чисел ), нормируем и т. п.
Более общий способ взвешивания даёт максимизация взвешенной суммы попарных расстояний между проекциями. Для каждых двух точек данных, вводится вес ; и . Вместо эмпирической ковариационной матрицы используется
При симметричная матрица положительно определена, поскольку положительна квадратичная форма:
Далее ищем ортонормированный собственный базис , упорядочиваем его по убыванию собственных значений, оцениваем средневзвешенную ошибку аппроксимации данных первыми компонентами и т. д. - в точности так же, как и в основном алгоритме.
Этот способ применяется при наличии классов : для из разных классов вес вес выбирается бо́льшим, чем для точек одного класса. В результате, в проекции на взвешенные главные компоненты различные классы «раздвигаются» на большее расстояние.
Другое применение - снижение влияния больших уклонений (оутлайеров, англ. Outlier ), которые могут искажать картину из-за использования среднеквадратичного расстояния: если выбрать , то влияние больших уклонений будет уменьшено. Таким образом, описанная модификация метода главных компонент является более робастной , чем классическая.
Специальная терминология
В статистике при использовании метода главных компонент используют несколько специальных терминов.
Матрица данных ; каждая строка - вектор предобработанных данных (центрированных и правильно нормированных ), число строк - (количество векторов данных), число столбцов - (размерность пространства данных);
Матрица нагрузок (Loadings) ; каждый столбец - вектор главных компонент, число строк - (размерность пространства данных), число столбцов - (количество векторов главных компонент, выбранных для проецирования);
Матрица счетов (Scores) ; каждая строка - проекция вектора данных на главных компонент; число строк - (количество векторов данных), число столбцов - (количество векторов главных компонент, выбранных для проецирования);
Матрица Z-счетов (Z-scores) ; каждая строка - проекция вектора данных на главных компонент, нормированная на единичную выборочную дисперсию; число строк - (количество векторов данных), число столбцов - (количество векторов главных компонент, выбранных для проецирования);
Матрица ошибок (или остатков ) (Errors or residuals) .
Основная формула:
Пределы применимости и ограничения эффективности метода
Метод главных компонент применим всегда. Распространённое утверждение о том, что он применим только к нормально распределённым данным (или для распределений, близких к нормальным) неверно: в исходной формулировке К. Пирсона ставится задача об аппроксимации конечного множества данных и отсутствует даже гипотеза о их статистическом порождении, не говоря уж о распределении.
Однако метод не всегда эффективно снижает размерность при заданных ограничениях на точность . Прямые и плоскости не всегда обеспечивают хорошую аппроксимацию. Например, данные могут с хорошей точностью следовать какой-нибудь кривой, а эта кривая может быть сложно расположена в пространстве данных. В этом случае метод главных компонент для приемлемой точности потребует нескольких компонент (вместо одной), или вообще не даст снижения размерности при приемлемой точности. Для работы с такими «кривыми» главными компонентами изобретен метод главных многообразий и различные версии нелинейного метода главных компонент . Больше неприятностей могут доставить данные сложной топологии. Для их аппроксимации также изобретены различные методы, например самоорганизующиеся карты Кохонена , нейронный газ или топологические грамматики . Если данные статистически порождены с распределением, сильно отличающимся от нормального, то для аппроксимации распределения полезно перейти от главных компонент к независимым компонентам , которые уже не ортогональны в исходном скалярном произведении. Наконец, для изотропного распределения (даже нормального) вместо эллипсоида рассеяния получаем шар, и уменьшить размерность методами аппроксимации невозможно.
Примеры использования
Визуализация данных
Визуализация данных - представление в наглядной форме данных эксперимента или результатов теоретического исследования.
Первым выбором в визуализации множества данных является ортогональное проецирование на плоскость первых двух главных компонент (или 3-мерное пространство первых трёх главных компонент). Плоскость проектирования является, по сути плоским двумерным «экраном», расположенным таким образом, чтобы обеспечить «картинку» данных с наименьшими искажениями. Такая проекция будет оптимальна (среди всех ортогональных проекций на разные двумерные экраны) в трех отношениях:
- Минимальна сумма квадратов расстояний от точек данных до проекций на плоскость первых главных компонент, то есть экран расположен максимально близко по отношению к облаку точек.
- Минимальна сумма искажений квадратов расстояний между всеми парами точек из облака данных после проецирования точек на плоскость.
- Минимальна сумма искажений квадратов расстояний между всеми точками данных и их «центром тяжести».
Визуализация данных является одним из наиболее широко используемых приложений метода главных компонент и его нелинейных обобщений .
Компрессия изображений и видео
Для уменьшения пространственной избыточности пикселей при кодировании изображений и видео используется линейные преобразования блоков пикселей. Последующие квантования полученных коэффициентов и кодирование без потерь позволяют получить значительные коэффициенты сжатия. Использование преобразования PCA в качестве линейного преобразования является для некоторых типов данных оптимальным с точки зрения размера полученных данных при одинаковом искажении . На данный момент этот метод активно не используется, в основном из-за большой вычислительной сложности. Также сжатия данных можно достичь отбрасывая последние коэффициенты преобразования.
Подавление шума на изображениях
Хемометрика
Метод главных компонент - один из основных методов в хемометрике (англ. Chemometrics ). Позволяет разделить матрицу исходных данных X на две части: «содержательную» и «шум». По наиболее популярному определению «Хемометрика - это химическая дисциплина, применяющая математические, статистические и другие методы, основанные на формальной логике, для построения или отбора оптимальных методов измерения и планов эксперимента, а также для извлечения наиболее важной информации при анализе экспериментальных данных».
Психодиагностика
- анализ данных (описание результатов опросов или других исследований, представленных в виде массивов числовых данных);
- описание социальных явлений (построение моделей явлений, в том числе и математических моделей).
В политологии метод главных компонент был основным инструментом проекта «Политический Атлас Современности» для линейного и нелинейного анализа рейтингов 192 стран мира по пяти специально разработанным интегральным индексам (уровня жизни, международного влияния, угроз, государственности и демократии). Для картографии результатов этого анализа разработана специальная ГИС (Геоинформационная система), объединяющая географическое пространство с пространством признаков. Также созданы карты данных политического атласа , использующие в качестве подложки двумерные главные многообразия в пятимерном пространстве стран. Отличие карты данных от географической карты заключается в том, что на географической карте рядом оказываются объекты, которые имеют сходные географические координаты, в то время как на карте данных рядом оказываются объекты (страны) с похожими признаками (индексами).