Основные понятия, используемые при проверке гипотез. Нулевая и альтернативная гипотезы От общего к частному: гипотезы в статистике
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ
Полученные в экспериментах выборочные данные всегда ограничены и носят в значительной мере случайный характер. Именно поэтому для анализа таких данных и используется математическая статистика, позволяющая обобщать закономерности, полученные на выборке, и распространять их на всю генеральную совокупность.
Полученные в результате эксперимента на какой-либо выборке данные служат основанием для суждения о генеральной совокупности. Однако в силу действия случайных вероятностных причин оценка параметров генеральной совокупности, сделанная на основании экспериментальных (выборочных) данных, всегда будет сопровождаться погрешностью, и поэтому подобного рода оценки должны рассматриваться как предположительные, а не как окончательные утверждения. Подобные предположения о свойствах и параметрах генеральной совокупности получили название статистических гипотез . Как указывает Г.В. Суходольский: «Под статистической гипотезой обычно понимают формальное предположение о том, что сходство (или различие) некоторых параметрических или функциональных характеристик случайно или, наоборот, неслучайно» .
Сущность проверки статистической гипотезы заключается в том, чтобы установить, согласуются ли экспериментальные данные и выдвинутая гипотеза, допустимо ли отнести расхождение между гипотезой и результатом статистического анализа экспериментальных данных за счет случайных причин. Таким образом, статистическая гипотеза – это научная гипотеза, допускающая статистическую проверку, а математическая статистика – это научная дисциплина, задачей которой является научно обоснованная проверка статистических гипотез.
Статистические гипотезы подразделяются на нулевые и альтернативные, направленные и ненаправленные.

Нулевая гипотеза (H 0 ) – это гипотеза об отсутствии различий. Если мы хотим доказать значимость различий, то нулевую гипотезу требуется опровергнуть , иначе требуется подтвердить .
Альтернативная гипотеза (Н 1 ) – гипотеза о значимости различий. Это то, что мы хотим доказать, поэтому иногда ее называют экспериментальной гипотезой.
Бывают задачи, когда мы хотим доказать как раз незначимость различий, то есть подтвердить нулевую гипотезу. Например, если нам нужно убедиться, что разные испытуемые получают хотя и различные, но уравновешенные по трудности заданияили что экспериментальная и контрольная выборки не различаются между собой по каким-то значимым характеристикам. Однако чаще нам все-таки требуется доказать значимость различий, ибо они более информативны для нас в поиске нового.
Нулевая и альтернативная гипотезы могут быть направленными и ненаправленными.
Направленные гипотезы – если предполагается в одной группе значения признака выше, а в другой ниже:
Н 0: Х 1 не превышает Х 2 ,
Н 1: Х 1 превышает Х 2 .
Ненаправленные гипотезы – если предполагается что различаются формы распределения признака в группах:
Н 0: Х 1 не отличается от Х 2 ,
Н 1: Х 1 отличается Х 2 .
Если мы заметили, что в одной из групп индивидуальные значения испытуемых по какому-либо признаку, например по социальной активности, выше, а в другой ниже, то для проверки значимости этих различий нам необходимо сформулировать направленные гипотезы.
Если мы хотим доказать, что в группе А под влиянием каких-то экспериментальных воздействий произошли более выраженные изменения, чем в группе Б , то нам тоже необходимо сформулировать направленные гипотезы.
Если же мы хотим доказать, что различаются формы распределения признака в группах А и Б , то формулируются ненаправленные гипотезы.
Проверка гипотез осуществляется с помощью критериев статистической оценки различий.
Принимаемый вывод носит название статистического решения. Подчеркнем, что такое решение всегда вероятностно. При проверке гипотезы экспериментальные данные могут противоречить гипотезе Н 0 , тогда эта гипотеза отклоняется. В противном случае, т.е. если экспериментальные данные согласуются с гипотезой Н 0 , она не отклоняется. Часто в таких случаях говорят, что гипотеза Н 0 принимается. Отсюда видно, что статистическая проверка гипотез, основанная на экспериментальных выборочных данных, неизбежно связана с риском (вероятностью) принять ложное решение. При этом возможны ошибки двух родов. Ошибка первого рода произойдет, когда будет принято решение отклонить гипотезу Н 0 , хотя в действительности она оказывается верной. Ошибка второго рода произойдет, когда будет принято решение не отклонять гипотезу Н 0 , хотя в действительности она будет неверна. Очевидно, что и правильные выводы могут быть приняты также в двух случаях. В таблице 7.1 обобщено вышесказанное.
Таблица 7.1
Не исключено, что психолог может ошибиться в своем статистическом решении; как видим из таблицы 7.1, эти ошибки могут быть только двух родов. Поскольку исключить ошибки при принятии статистических гипотез невозможно, то необходимо минимизировать возможные последствия, т.е. принятие неверной статистической гипотезы. В большинстве случаев единственный путь минимизации ошибок заключается в увеличении объема выборки.
СТАТИСТИЧЕСКИЕ КРИТЕРИИ
Статистический критерий – это решающее правило, обеспечивающее надежное поведение, то есть принятие истинной и отклонение ложной гипотезы с высокой вероятностью .
Статистические критерии обозначают также метод расчета определенного числа и само это число.
Когда мы говорим, что достоверность различий определялась по критерию j * (критерий – угловое преобразование Фишера), то имеем в виду, что использовали метод j * для расчета определенного числа.
По соотношению эмпирического и критического значений критерия мы можем судить о том, подтверждается ли или опровергается нулевая гипотеза.
В большинстве случаев для того, чтобы мы признали различия значимыми, необходимо, чтобы эмпирическое значение критерия превышало критическое, хотя есть критерии (например, критерий Манна-Уитни или критерий знаков), в которых мы должны придерживаться противоположного правила.
В некоторых случаях расчетная формула критерия включает в себя количество наблюдений в исследуемой выборке, обозначаемое как n . В этом случае эмпирическое значение критерия одновременно является тестом для проверки статистических гипотез. По специальной таблице мы определяем, какому уровню статистической значимости различий соответствует данная эмпирическая величина. Примером такого критерия является критерий j * , вычисляемый на основе углового преобразования Фишера.
В большинстве случаев, однако, одно и то же эмпирическое значение критерия может оказаться значимым или незначимым в зависимости от количества наблюдений в исследуемой выборке (n ) или от так называемого количества степеней свободы, которое обозначается как v или как df.
Число степеней свободы v равно числу классов вариационного ряда минус число условий, при которых он был сформирован. К числу таких условий относятся объем выборки (n ), средние и дисперсии.
Допустим, группу из 50 человек разделили на три класса по принципу:
Умеет работать на компьютере;
Умеет выполнять лишь определенные операции;
Не умеет работать на компьютере.
В первую и вторую группы попало по 20 человек, в третью – 10.
Мы ограничены одним условием – объемом выборки. Поэтому, даже если мы потеряли данные о том, сколько человек не умеют работать на компьютере, мы можем определить это, зная, что в первом и втором классах – по 20 испытуемых. Мы не свободны в определении количества испытуемых в третьем разряде, «свобода» простирается только на первые две ячейки классификации:

СТАТИСТИЧЕСКАЯ ПРОВЕРКА СТАТИСТИЧЕСКИХ
Понятие статистической гипотезы.
Виды гипотез. Ошибки первого и второго рода
Гипотеза - это предположение о некоторых свойствах изучаемых явлений. Под статистической гипотезой понимают всякое высказывание о генеральной совокупности, которое можно проверить статистически, то есть опираясь на результаты наблюдений в случайной выборке. Рассматривают два вида статистических гипотез: гипотезы о законах распределения генеральной совокупности и гипотезы о параметрах известных распределений.
Так, гипотеза о том, что затраты времени на сборку узла машины в группе механических цехов, выпускающих продукцию одного наименования и имеющих примерно одинаковые технико-экономические условия производства, распределяются по нормальному закону, является гипотезой о законе распределения. А гипотеза о том, что производительность труда рабочих в двух бригадах, выполняющих одну и ту же работу в одинаковых условиях, не различается (при этом производительность труда рабочих каждой бригады имеет нормальный закон распределения), является гипотезой о параметрах распределения.
Подлежащая проверке гипотеза называется нулевой, или основной, и обозначается Н 0 . Нулевой гипотезе противопоставляют конкурирующую, или альтернативную, гипотезу, которую обозначают Н 1 . Как правило, конкурирующая гипотеза Н 1 является логическим отрицанием основной гипотезы Н 0.
Примером нулевой гипотезы может быть следующая: средние двух нормально распределенных генеральных совокупностей равны, тогда конкурирующая гипотеза может состоять из предположения, что средние не равны. Символически это записывается так:
Н 0: М (Х ) = М (Y ); Н 1: М (Х ) М (Y ) .
Если нулевая (выдвинутая) гипотеза будет отвергнута, то имеет место конкурирующая гипотеза.
Различают гипотезы простые и сложные. Если гипотеза содержит только одно предположение, то это - простая гипотеза. Сложная гипотеза состоит из конечного или бесконечного числа простых гипотез.
Например, гипотеза Н 0: p = p 0 (неизвестная вероятность p равна гипотетической вероятности p 0 ) - простая, а гипотеза Н 0: p < p 0 - сложная, она состоит из бесчисленного множества простых гипотез вида Н 0: p = p i , где p i - любое число, меньше p 0 .
Выдвигаемая статистическая гипотеза может быть правильной или неправильной, поэтому необходимо ее проверить , опираясь на результаты наблюдений в случайной выборке; проверку производят статистическими методами , поэтому ее называют статистической.
При проверке статистической гипотезы пользуются специально составленной случайной величиной, называемой статистическим критерием (или статистикой ). Принимаемое заключение о правильности (или неправильности) гипотезы основывается на изучении распределения этой случайной величины по данным выборки. Поэтому статистическая проверка гипотез имеет вероятностный характер: всегда существует риск допустить ошибку при принятии (отклонении) гипотезы. При этом возможны ошибки двух родов.
Ошибка первого рода состоит в том, что будет отвергнута нулевая гипотеза, хотя на самом деле она верна.
Ошибка второго рода состоит в том, что будет принята нулевая гипотеза, хотя в действительности верна конкурирующая.
В большинстве случаев последствия указанных ошибок неравнозначны. Что лучше или хуже - зависит от конкретной постановки задачи и содержания нулевой гипотезы. Рассмотрим примеры. Допустим, что на предприятии о качестве продукции судят по результатам выборочного контроля. Если выборочная доля брака не превышает заранее установленной величины p 0 , то партия принимается. Другими словами, выдвигается нулевая гипотеза: Н 0: p p 0 . Если при проверке этой гипотезы допущена ошибка первого рода, то мы забракуем годную продукцию. Если же совершена ошибка второго рода, то потребителю будет отправлен брак. Очевидно, что последствия ошибки второго рода могут быть значительно более серьезными.
Другой пример можно привести из области юриспруденции. Будем рассматривать работу судей как действия по проверке презумпции невиновности подсудимого. В качестве основной проверяемой гипотезы следует рассмотреть гипотезу Н 0 : подсудимый невиновен. Тогда альтернативной гипотезой Н 1 является гипотеза: обвиняемый виновен в совершении преступления. Очевидно, что суд может совершить ошибки первого или второго рода при вынесении приговора подсудимому. Если допущена ошибка первого рода, то это означает, что суд наказал невиновного: подсудимому был вынесен обвинительный приговор, когда на самом деле он не совершал преступления. Если же судьи допустили ошибку второго рода, то это значит, что суд вынес оправдательный приговор, когда на самом деле обвиняемый виновен в совершении преступления. Очевидно, что последствия ошибки первого рода для обвиняемого будут значительно более серьезными, в то время как для общества наиболее опасными являются последствия ошибки второго рода.
Вероятность совершить ошибку первого рода называют уровнем значимости критерия и обозначают .
В большинстве случаев уровень значимости критерия принимают равным 0,01 или 0,05. Если, например, уровень значимости принят равным 0,01, то это означает, что в одном случае из ста имеется риск допустить ошибку первого рода (то есть отвергнуть правильную нулевую гипотезу).
Вероятность
совершить ошибку
второго рода
обозначают
.
Вероятность
 не совершить ошибку второго рода, то
есть отвергнуть нулевую гипотезу, когда
она неверна, называется
мощностью критерия.
не совершить ошибку второго рода, то
есть отвергнуть нулевую гипотезу, когда
она неверна, называется
мощностью критерия.
Статистический критерий.
Критические области
Статистическую гипотезу проверяют с помощью специально подобранной случайной величины, точное или приближенное распределение которой известно (обозначим ее К ). Эту случайную величину называют статистическим критерием (или просто критерием ).
Существуют различные статистические критерии, применяемые на практике: U - и Z -критерии (эти случайные величины имеют нормальное распределение); F -критерий (случайная величина распределена по закону Фишера - Снедекора); t -критерий (по закону Стьюдента); -критерий (по закону "хи-квадрат") и др.
Множество всех возможных значений критерия можно разбить на два непересекающихся подмножества: одно из них содержит значения критерия, при которых нулевая гипотеза принимается, а другое - при которых она отвергается.
Множество значений критерия, при которых нулевая гипотеза отвергается, называется критической областью . Будем обозначать критическую область через W .
Множество
значений критерия, при которых нулевая
гипотеза принимается, называется
областью
принятия гипотезы
(или
областью
допустимых значений критерия
).
Будем обозначать эту область как
 .
.
Для проверки справедливости нулевой гипотезы по данным выборок вычисляют наблюдаемое значение критерия . Будем обозначать его К набл.
Основной
принцип проверки статистических гипотез
можно сформулировать так: если наблюдаемое
значение критерия попало в критическую
область (то есть
 ),
то нулевую гипотезу отвергают; если же
наблюдаемое значение критерия попало
в область принятия гипотезы (то есть
),
то нулевую гипотезу отвергают; если же
наблюдаемое значение критерия попало
в область принятия гипотезы (то есть
 ),
то нет оснований отвергать нулевую
гипотезу.
),
то нет оснований отвергать нулевую
гипотезу.
Какими принципами следует руководствоваться при построении критической области W ?
Допустим,
что гипотеза Н
0
на
самом деле верна. Тогда попадание
критерия
 в критическую область в силу основного
принципа проверки статистических
гипотез влечет за собой отклонение
верной гипотезы Н
0
, а
значит, совершение ошибки первого рода.
Поэтому вероятность попадания
в критическую область в силу основного
принципа проверки статистических
гипотез влечет за собой отклонение
верной гипотезы Н
0
, а
значит, совершение ошибки первого рода.
Поэтому вероятность попадания
 в область W
при справедливости
гипотезы Н
0
должна быть
равна уровню значимости критерия, то
есть
в область W
при справедливости
гипотезы Н
0
должна быть
равна уровню значимости критерия, то
есть
 .
.
Заметим,
что вероятность совершить ошибку первого
рода выбирается достаточно малой (как
правило,
 ).
Тогда попадание критерия
).
Тогда попадание критерия
 в критическую область W
при
справедливости гипотезы Н
0
можно считать практически невозможным
событием. Если по данным выборочного
наблюдения событие
в критическую область W
при
справедливости гипотезы Н
0
можно считать практически невозможным
событием. Если по данным выборочного
наблюдения событие
 все же наступило, то его можно считать
несовместимым с гипотезой Н
0
(которая в результате и отвергается),
но совместимым с гипотезой Н
1
(которая в результате принимается).
все же наступило, то его можно считать
несовместимым с гипотезой Н
0
(которая в результате и отвергается),
но совместимым с гипотезой Н
1
(которая в результате принимается).
Предположим
теперь, что верна гипотеза Н
1
.
Тогда попадание критерия
 в область принятия гипотезы
в область принятия гипотезы
 влечет за собой принятие неверной
гипотезы Н
0
, что означает
совершение ошибки второго рода. Поэтому
влечет за собой принятие неверной
гипотезы Н
0
, что означает
совершение ошибки второго рода. Поэтому
 .
.
Так
как события
 и
и
 являются взаимно противоположными, то
вероятность попадания критерия
являются взаимно противоположными, то
вероятность попадания критерия
 в критическую область W
будет равна
мощности критерия, если гипотеза Н
1
верна, то
есть
в критическую область W
будет равна
мощности критерия, если гипотеза Н
1
верна, то
есть
 .
.
Очевидно,
что критическую область следует выбирать
так, чтобы при заданном уровне значимости
мощность критерия
 была максимальной. Максимизация мощности
критерия обеспечит минимум вероятности
допустить ошибку второго рода.
была максимальной. Максимизация мощности
критерия обеспечит минимум вероятности
допустить ошибку второго рода.
Следует отметить, что как бы ни было мало значение уровня значимости , попадание критерия в критическую область есть только маловероятное, но не абсолютно невозможное событие. Поэтому не исключено, что при верной нулевой гипотезе значение критерия, вычисленное по данным выборки, все же окажется в критической области. Отклоняя в этом случае гипотезу Н 0 , мы допускаем ошибку первого рода с вероятностью . Чем меньше , тем менее вероятно допустить ошибку первого рода. Однако с уменьшением уменьшается критическая область, а значит, становится менее возможным попадание в нее наблюдаемого значения К набл, даже когда гипотеза Н 0 неверна. При =0 гипотеза Н 0 всегда будет приниматься независимо от результатов выборки. Поэтому уменьшение влечет за собой увеличение вероятности принять неверную нулевую гипотезу, то есть совершить ошибку второго рода. В этом смысле ошибки первого и второго рода являются конкурирующими.
Так как исключить ошибки первого и второго рода невозможно, необходимо хотя бы стремиться в каждом конкретном случае свести к минимуму потери от этих ошибок. Конечно, желательно уменьшить обе ошибки одновременно, но так как они являются конкурирующими, то уменьшение вероятности допустить одну из них влечет увеличение вероятности допустить другую. Единственный путь одновременного уменьшения риска ошибок заключается в увеличении объема выборки .
В
зависимости от вида конкурирующей
гипотезы Н
1
строят
одностороннюю (правостороннюю и
левостороннюю) и двустороннюю критические
области.
Точки, отделяющие критическую
область
 от
области принятия гипотезы
от
области принятия гипотезы
 ,
называют критическими точками
и
обозначают k
крит.
Для отыскания критической области
необходимо знать критические точки.
,
называют критическими точками
и
обозначают k
крит.
Для отыскания критической области
необходимо знать критические точки.
Правосторонняя
критическая область может быть описана
неравенством
 К
>k
крит.
пр, где предполагается, что правая
критическая точка k
крит.
пр >0. Такая область состоит из точек,
находящихся по правую сторону от
критической точки k
крит.
пр, то есть она содержит множество
положительных и достаточно больших
значений критерия К.
Для нахождения
k
крит. пр задают
сначала уровень значимости критерия
.
Далее правую критическую точку k
крит.
пр находят из условия
.
Почему именно это требование определяет
правостороннюю критическую область?
Так как вероятность события (К
>k
крит.
пр )
мала, то, в силу принципа
практической невозможности маловероятных
событий, это событие при справедливости
нулевой гипотезы в единичном испытании
не должно наступить. Если все же оно
наступило, то есть вычисленное по данным
выборок наблюдаемое значение критерия
К
>k
крит.
пр, где предполагается, что правая
критическая точка k
крит.
пр >0. Такая область состоит из точек,
находящихся по правую сторону от
критической точки k
крит.
пр, то есть она содержит множество
положительных и достаточно больших
значений критерия К.
Для нахождения
k
крит. пр задают
сначала уровень значимости критерия
.
Далее правую критическую точку k
крит.
пр находят из условия
.
Почему именно это требование определяет
правостороннюю критическую область?
Так как вероятность события (К
>k
крит.
пр )
мала, то, в силу принципа
практической невозможности маловероятных
событий, это событие при справедливости
нулевой гипотезы в единичном испытании
не должно наступить. Если все же оно
наступило, то есть вычисленное по данным
выборок наблюдаемое значение критерия
 оказалось больше k
крит.
пр, то это можно объяснить тем, что
нулевая гипотеза не согласуется с
данными наблюдения и поэтому должна
быть отвергнута. Таким образом, требование
оказалось больше k
крит.
пр, то это можно объяснить тем, что
нулевая гипотеза не согласуется с
данными наблюдения и поэтому должна
быть отвергнута. Таким образом, требование
 определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Если
же
 попало в область допустимых значений
критерия
попало в область допустимых значений
критерия
 ,
то есть
,
то есть
 <
k
крит. пр, то
основная гипотеза не отвергается, ибо
она совместима с данными наблюдения.
Заметим, что вероятность попадания
критерия
<
k
крит. пр, то
основная гипотеза не отвергается, ибо
она совместима с данными наблюдения.
Заметим, что вероятность попадания
критерия
 в область допустимых значений
в область допустимых значений
 при справедливости нулевой гипотезы
равна (1-)
и близка к 1.
при справедливости нулевой гипотезы
равна (1-)
и близка к 1.
Необходимо
помнить, что попадание значений критерия
 в
область допустимых значений не является
строгим доказательством справедливости
нулевой гипотезы. Оно лишь указывает,
что между выдвигаемой гипотезой и
результатами выборки нет существенного
расхождения. Поэтому в таких случаях
говорят, что данные наблюдений согласуются
с нулевой гипотезой и нет оснований
отвергать ее.
в
область допустимых значений не является
строгим доказательством справедливости
нулевой гипотезы. Оно лишь указывает,
что между выдвигаемой гипотезой и
результатами выборки нет существенного
расхождения. Поэтому в таких случаях
говорят, что данные наблюдений согласуются
с нулевой гипотезой и нет оснований
отвергать ее.
Аналогично проводится построение и других критических областей.
Так,
л
евосторонняя
критическая
область описывается неравенством
 К
<k
крит. л,
где k
крит.л <0.
Такая область состоит из точек, находящихся
по левую сторону от левой критической
точки k
крит.л,
то есть она представляет собой множество
отрицательных, но достаточно больших
по модулю значений критерия. Критическую
точку k
крит.л
находят из условия
К
<k
крит. л,
где k
крит.л <0.
Такая область состоит из точек, находящихся
по левую сторону от левой критической
точки k
крит.л,
то есть она представляет собой множество
отрицательных, но достаточно больших
по модулю значений критерия. Критическую
точку k
крит.л
находят из условия
 (К
<k
крит.
л)
(К
<k
крит.
л) ,
то есть вероятность того, что критерий
принимает значение, меньшее k
крит.л,
равна принятому уровню значимости
,
если нулевая гипотеза верна.
,
то есть вероятность того, что критерий
принимает значение, меньшее k
крит.л,
равна принятому уровню значимости
,
если нулевая гипотеза верна.
Двусторонняя
критическая область
 описывается
следующими неравенствами: (К<
k
крит.л
или К
>k
крит.
пр), где предполагается, что k
крит.л <0
и k
крит. пр >0.
Такая область представляет собой
множество достаточно больших по модулю
значений критерия. Критические точки
находят из требования: сумма вероятностей
того, что критерий примет значение,
меньшее k
крит. л
или больше k
крит.
пр, должна быть равна принятому
уровню значимости при справедливости
нулевой гипотезы, то есть
описывается
следующими неравенствами: (К<
k
крит.л
или К
>k
крит.
пр), где предполагается, что k
крит.л <0
и k
крит. пр >0.
Такая область представляет собой
множество достаточно больших по модулю
значений критерия. Критические точки
находят из требования: сумма вероятностей
того, что критерий примет значение,
меньшее k
крит. л
или больше k
крит.
пр, должна быть равна принятому
уровню значимости при справедливости
нулевой гипотезы, то есть
 (К<
k
крит.
л )+
(К<
k
крит.
л )+
 (К
>k
крит.
пр )=
.
(К
>k
крит.
пр )=
.
Если распределение критерия К симметрично относительно начала координат, то критические точки будут располагаться симметрично относительно нуля, поэтому k крит. л = - k крит. пр. Тогда двусторонняя критическая область становится симметричной и может быть описана следующим неравенством: > k крит. дв, где k крит. дв = k крит. пр Критическую точку k крит. дв можно найти из условия
Р(К< -k крит. дв )=Р(К >k крит. дв )= .
Замечание
1.
Для каждого критерия К
критические
точки при заданном уровне значимости
 могут быть найдены из условия
могут быть найдены из условия
 только численно. Результаты численных
вычислений
k
крит
приведены в соответствующих таблицах
(см., например, прил. 4 – 6 в файле
«Приложения»).
только численно. Результаты численных
вычислений
k
крит
приведены в соответствующих таблицах
(см., например, прил. 4 – 6 в файле
«Приложения»).
Замечание 2. Описанный выше принцип проверки статистической гипотезы не доказывает еще ее истинность или неистинность. Принятие гипотезы Н 0 в сравнении с альтернативной гипотезой Н 1 не означает, что мы уверены в абсолютной правильности гипотезы Н 0 - просто гипотеза Н 0 согласуется с имеющимися у нас данными наблюдения, то есть является достаточно правдоподобным, не противоречащим опыту утверждением. Возможно, что с увеличением объема выборки n гипотеза Н 0 будет отвергнута.
Формулирование гипотез систематизирует предположения исследователя и представляет их в четком, лаконичном виде. Решение, которое требуется принять исследователю, касается истинности или ложности статистической гипотезы. Различают два вида гипотез: научные и статистические. Научная гипотеза – это предполагаемое решение проблемы (формулируется как теорема). Статистическая гипотеза – просто утверждение относительно неизвестного параметра генеральной совокупности (свойстве случайной величины или событии), которое формулируется для проверки надежности связи и которое можно проверить по известным выборочным статистикам (результатам исследования, имеющимся эмпирическим данным) .
Статистические гипотезы подразделяются на нулевые и альтернативные, направленные и ненаправленные. Нулевая гипотеза (Н 0) это гипотеза об отсутствии различий, отсутствие влияния фактора, отсутствие эффекта и т.п . Это то, что предполагается опровергнуть, если перед нами стоит задача доказать значимость различий. Альтернативная гипотеза (Н 1) это гипотеза о значимости различий. Это то, что предполагается доказать, поэтому ее иногда называют экспериментальной или рабочей гипотезой.
Сама же процедура обработки полученных количественных данных, заключающаяся в вычислении некоторых статистических характеристик и оценок, позволяющих проверить нулевую гипотезу называется статистическим анализом .
Нулевая и альтернативная гипотезы могут быть направленными и ненаправленными. Гипотеза называется направленной , если она содержит указание на направление отличий. Такие гипотезы следует формулировать, например, в том случае, если в одной из групп индивидуальные значения испытуемых по какому-либо признаку выше, а в другой ниже, или необходимо доказать, что в одной из групп под влиянием каких-либо экспериментальных воздействий произошли более выраженные изменения, чем в другой группе. Гипотеза называется ненаправленной , если ее формулировка предполагает лишь определение отличий или не отличий (без указания направления отличий). Например, если необходимо доказать, в двух разных группах различаются формы распределения признака.
Примеры формулирования гипотез.
Метод, который используется для принятия решения относительно справедливости статистической гипотезы, называется проверкой гипотезы . Основной принцип проверки гипотезы состоит в том, что выдвигается нулевая гипотеза Н 0 , с тем, чтобы попытаться опровергнуть ее и тем самым подтвердить альтернативную гипотезу Н 1 .
При проверке любой статистической гипотезы решение исследователя никогда не принимается с уверенностью, поскольку всегда остается риск принятия неправильного решения.
Обычно используемые выборки невелики, и в этих случаях вероятность ошибки может быть значительной. Существует так называемый уровень достоверности (уровень значимости) различия. Это вероятность того, что различия считаются существенными, а они на самом деле случайны. То есть это вероятность отклонения нулевой гипотезы, в то время как она верна.
Когда указывается, что различия достоверны на 5%-ном уровне значимости, или при p£0,05, то имеется в виду, что вероятность того, что они все-таки недостоверны, составляет 0,05 (низший уровень статистической значимости). Если указывается, что различия достоверны на 1%-ном уровне значимости, или при p£0,01, то имеется в виду, что вероятность того, что они все-таки недостоверны, составляет 0,01 (достаточный уровень статистической значимости). Если указывается, что различия достоверны на 0,1%-ном уровне значимости, или при p£0,001, то имеется в виду, что вероятность того, что они все-таки недостоверны, составляет 0,001 (высший уровень статистической значимости).
Правило отклонения Н 0 и принятия Н 1:
Если эмпирическое значение критерия равняется критическому значению, соответствующему p£0,05 или превышает его, то Н 0 отклоняется, но еще нельзя определенно принять Н 1 .
Если эмпирическое значение критерия равняется критическому значению, соответствующему p£0,01 или превышает его, то Н 0 отклоняется принимается Н 1 .
Для наглядности правила принятия решения можно использовать так называемую «ось значимости».
Если уровень достоверности не превышен, то можно считать вероятным, что выявленная разница действительно отражает положение дел в популяции. Для каждого статистического метода этот уровень можно узнать из таблиц распределения критических значений соответствующих критериев.
T – критерий Стьюдента
Это параметрический метод, используемый для проверки гипотез о достоверности разницы средних при анализе количественных данных в популяциях с нормальным распределением и с одинаковой дисперсией. Он хорошо применим в случае сравнения величин средних случайных значений измеряемого признака в контрольной и экспериментальной группах, в различных половозрастных группах, группах, имеющих другие различные признаки.
Обязательным условием применимости параметрических методов, в том числе и t‑критерия Стьюдента, для доказательства статистических гипотез является подчинение эмпирического распределения исследуемого признака закону нормального распределения .
Метод Стьюдента различен для независимых и зависимых выборок.
Независимые выборки получаются при исследовании двух различных групп испытуемых (например, контрольной и опытной групп). К зависимым выборкам относятся, например, результаты одной и той же группы испытуемых до и после воздействия независимой переменной.
Проверяемая гипотеза Н 0 состоит в том, что разность между средними значениями двух выборок равна нулю ( = 0), другими словами это гипотеза о равенстве средних (). Альтернативная гипотеза Н 1 состоит в том, что эта разность отлична от нуля ( ¹ 0) или же существует отличие выборочных средних ().
В случае независимых выборок
для анализа разницы средних применяют формулу:  при n 1 , n 2 > 30
при n 1 , n 2 > 30
и формулу  при n 1 , n 2 < 30, где
при n 1 , n 2 < 30, где
Среднее арифметическое значение первой выборки;
Среднее арифметической значение второй выборки;
s 1 – стандартное отклонение для первой выборки;
s 2 – стандартное отклонение для второй выборки;
n 1 и n 2 – число элементов в первой и второй выборках.
Для нахождения критического значения t определим число степеней свободы:
n = n 1 - 1 + n 2 - 1 = (n 1 + n 2) – 2 = n - 2.
Если |t эмп | > t кр, то нулевую гипотезу отбрасываем и принимаем альтернативную, то есть считаем разницу средних достоверной. Если |t эмп | < t кр, то разница средних недостоверна.
В случае зависимых выборок
для определения достоверности разницы средних применяется следующая формула:  , где
, где
d – разность между результатами в каждой паре (х i – y i);
åd – сумма этих частных разностей;
åd 2 – сумма квадратов частных разностей;
n – число пар данных.
Число степеней свободы в случае зависимых выборок для определения t критерия будет равно n = n - 1.
Существуют и другие статистические критерии проверки гипотез, как параметрические, так и непараметрические. Например, математико-статистический критерий, позволяющий судить о сходстве и различиях в дисперсиях случайных величин, называется критерием Фишера.
В самом общем виде под значением «корреляция» понимается взаимная связь. Хотя, говоря о корреляции, используют также термины «корреляционная связь» и «корреляционная зависимость», которые часто используются как синонимы.
Под корреляционной связью понимают согласованные изменения двух или большего количества признаков, т.е. изменчивость одного признака находится в некотором соответствии с изменчивостью другого.
Корреляционная зависимость - это изменения, которые вносят значения одного признака в вероятность появления разных значений другого признака.
Таким образом, согласованные изменения признаков и отражающая это корреляционная связь между ними может свидетельствовать не о зависимости этих признаков между собой, а о зависимости обоих этих признаков от какого-то третьего признака или сочетания признаков, не рассматриваемых в исследовании.
5. Основные проблемы прикладной статистики - описание данных, оценивание и проверка гипотез
Основные понятия, используемые при проверке гипотез
Статистическая гипотеза – любое предположение, касающееся неизвестного распределения случайных величин (элементов). Приведем формулировки нескольких статистических гипотез:
1. Результаты наблюдений имеют нормальное распределение с
нулевым математическим ожиданием.
2. Результаты наблюдений имеют функцию распределения N
(0,1).
3. Результаты наблюдений имеют нормальное распределение.
4. Результаты наблюдений в двух независимых выборках имеют
одно и то же нормальное распределение.
5.
Результаты наблюдений в двух независимых выборках имеют одно и то же
распределение.
Различают нулевую и альтернативную гипотезы. Нулевая гипотеза – гипотеза, подлежащая проверке. Альтернативная гипотеза – каждая допустимая гипотеза, отличная от нулевой. Нулевую гипотезу обозначают Н 0 , альтернативную – Н 1 (от Hypothesis – «гипотеза» (англ.)).
Выбор тех или иных нулевых или альтернативных гипотез определяется стоящими перед менеджером, экономистом, инженером, исследователем прикладными задачами. Рассмотрим примеры.
Пример 11. Пусть нулевая гипотеза – гипотеза 2 из приведенного выше списка, а альтернативная – гипотеза 1. Сказанное означает, то реальная ситуация описывается вероятностной моделью, согласно которой результаты наблюдений рассматриваются как реализации независимых одинаково распределенных случайных величин с функцией распределения N (0,σ), где параметр σ неизвестен статистику. В рамках этой модели нулевую гипотезу записывают так:
Н 0: σ = 1,
а альтернативную так:
Н 1: σ ≠ 1.
Пример 12. Пусть нулевая гипотеза – по-прежнему гипотеза 2 из приведенного выше списка, а альтернативная – гипотеза 3 из того же списка. Тогда в вероятностной модели управленческой, экономической или производственной ситуации предполагается, что результаты наблюдений образуют выборку из нормального распределения N (m , σ) при некоторых значениях m и σ. Гипотезы записываются так:
Н 0: m = 0, σ = 1
(оба параметра принимают фиксированные значения);
Н 1: m ≠ 0 и/или σ ≠ 1
(т.е. либо m ≠ 0, либо σ ≠ 1, либо и m ≠ 0, и σ ≠ 1).
Пример 13. Пусть Н 0 – гипотеза 1 из приведенного выше списка, а Н 1 – гипотеза 3 из того же списка. Тогда вероятностная модель – та же, что в примере 12,
Н 0: m = 0, σ произвольно;
Н 1: m ≠ 0, σ произвольно.
Пример 14. Пусть Н 0 – гипотеза 2 из приведенного выше списка, а согласно Н 1 результаты наблюдений имеют функцию распределения F (x ), не совпадающую с функцией стандартного нормального распределения Ф(х). Тогда
Н 0: F (х) = Ф(х) при всех х (записывается как F (х) ≡ Ф(х) );
Н 1: F (х 0) ≠ Ф(х 0) при некотором х 0 (т.е. неверно, что F (х) ≡ Ф(х) ).
Примечание. Здесь ≡ - знак тождественного совпадения функций (т.е. совпадения при всех возможных значениях аргумента х ).
Пример 15. Пусть Н 0 – гипотеза 3 из приведенного выше списка, а согласно Н 1 результаты наблюдений имеют функцию распределения F (x ), не являющуюся нормальной. Тогда
При некоторых m , σ;
Н
1: для любых m
, σ найдется х 0
= х 0
(m
, σ) такое, что ![]() .
.
Пример 16. Пусть Н 0 – гипотеза 4 из приведенного выше списка, согласно вероятностной модели две выборки извлечены из совокупностей с функциями распределения F (x ) и G (x ), являющихся нормальными с параметрами m 1 , σ 1 и m 2 , σ 2 соответственно, а Н 1 – отрицание Н 0 . Тогда
Н 0: m 1 = m 2 , σ 1 = σ 2 , причем m 1 и σ 1 произвольны;
Н 1: m 1 ≠ m 2 и/или σ 1 ≠ σ 2 .
Пример 17. Пусть в условиях примера 16 дополнительно известно, что σ 1 = σ 2 . Тогда
Н 0: m 1 = m 2 , σ > 0, причем m 1 и σ произвольны;
Н 1: m 1 ≠ m 2 , σ > 0.
Пример 18. Пусть Н 0 – гипотеза 5 из приведенного выше списка, согласно вероятностной модели две выборки извлечены из совокупностей с функциями распределения F (x ) и G (x ) соответственно, а Н 1 – отрицание Н 0 . Тогда
Н 0: F (x ) ≡ G (x ) , где F (x )
Н 1: F (x ) и G (x ) - произвольные функции распределения, причем
F (x ) ≠ G (x ) при некоторых х .
Пример 19. Пусть в условиях примера 17 дополнительно предполагается, что функции распределения F (x ) и G (x ) отличаются только сдвигом, т.е. G (x ) = F (x - а) при некотором а . Тогда
Н 0: F (x ) ≡ G (x ) ,
где F (x ) – произвольная функция распределения;
Н 1: G (x ) = F (x - а), а ≠ 0,
где F (x ) – произвольная функция распределения.
Пример 20. Пусть в условиях примера 14 дополнительно известно, что согласно вероятностной модели ситуации F (x ) - функция нормального распределения с единичной дисперсией, т.е. имеет вид N (m , 1). Тогда
Н 0: m = 0 (т.е. F (х) = Ф(х)
при всех х );(записывается как F (х) ≡ Ф(х) );
Н 1: m ≠ 0
(т.е. неверно, что F (х) ≡ Ф(х) ).
Пример 21. При статистическом регулировании технологических, экономических, управленческих или иных процессов рассматривают выборку, извлеченную из совокупности с нормальным распределением и известной дисперсией, и гипотезы
Н 0: m = m 0 ,
Н 1: m = m 1 ,
где значение параметра m = m 0 соответствует налаженному ходу процесса, а переход к m = m 1 свидетельствует о разладке.
Пример 22. При статистическом приемочном контроле число дефектных единиц продукции в выборке подчиняется гипергеометрическому распределению, неизвестным параметром является p = D / N – уровень дефектности, где N – объем партии продукции, D – общее число дефектных единиц продукции в партии. Используемые в нормативно-технической и коммерческой документации (стандартах, договорах на поставку и др.) планы контроля часто нацелены на проверку гипотезы
Н 0: p < AQL
Н 1: p > LQ ,
где AQL – приемочный уровень дефектности, LQ – браковочный уровень дефектности (очевидно, что AQL < LQ ).
Пример 23. В качестве показателей стабильности технологического, экономического, управленческого или иного процесса используют ряд характеристик распределений контролируемых показателей, в частности, коэффициент вариации v = σ/M (X ). Требуется проверить нулевую гипотезу
Н 0: v < v 0
при альтернативной гипотезе
Н 1: v > v 0 ,
где v 0 – некоторое заранее заданное граничное значение.
Пример 24. Пусть вероятностная модель двух выборок – та же, что в примере 18, математические ожидания результатов наблюдений в первой и второй выборках обозначим М (Х ) и М (У ) соответственно. В ряде ситуаций проверяют нулевую гипотезу
Н 0: М(Х) = М(У)
против альтернативной гипотезы
Н 1: М(Х) ≠ М(У).
Пример 25 . Выше отмечалось большое значение в математической статистике функций распределения, симметричных относительно 0, При проверке симметричности
Н 0: F (- x ) = 1 – F (x ) при всех x , в остальном F произвольна;
Н 1: F (- x 0 ) ≠ 1 – F (x 0 ) при некотором x 0 , в остальном F произвольна.
В вероятностно-статистических методах принятия решений используются и многие другие постановки задач проверки статистических гипотез. Некоторые из них рассматриваются ниже.
Конкретная задача проверки статистической гипотезы полностью описана, если заданы нулевая и альтернативная гипотезы. Выбор метода проверки статистической гипотезы, свойства и характеристики методов определяются как нулевой, так и альтернативной гипотезами. Для проверки одной и той же нулевой гипотезы при различных альтернативных гипотезах следует использовать, вообще говоря, различные методы. Так, в примерах 14 и 20 нулевая гипотеза одна и та же, а альтернативные – различны. Поэтому в условиях примера 14 следует применять методы, основанные на критериях согласия с параметрическим семейством (типа Колмогорова или типа омега-квадрат), а в условиях примера 20 – методы на основе критерия Стьюдента или критерия Крамера-Уэлча . Если в условиях примера 14 использовать критерий Стьюдента, то он не будет решать поставленных задач. Если в условиях примера 20 использовать критерий согласия типа Колмогорова, то он, напротив, будет решать поставленные задачи, хотя, возможно, и хуже, чем специально приспособленный для этого случая критерий Стьюдента.
При обработке реальных данных большое значение имеет правильный выбор гипотез Н 0 и Н 1 . Принимаемые предположения, например, нормальность распределения, должны быть тщательно обоснованы, в частности, статистическими методами. Отметим, что в подавляющем большинстве конкретных прикладных постановок распределение результатов наблюдений отлично от нормального .
Часто возникает ситуация, когда вид нулевой гипотезы вытекает из постановки прикладной задачи, а вид альтернативной гипотезы не ясен. В таких случаях следует рассматривать альтернативную гипотезу наиболее общего вида и использовать методы, решающие поставленную задачу при всех возможных Н 1 . В частности при проверке гипотезы 2 (из приведенного выше списка) как нулевой следует в качестве альтернативной гипотезы использовать Н 1 из примера 14, а не из примера 20, если нет специальных обоснований нормальности распределения результатов наблюдений при альтернативной гипотезе.
| Предыдущая |
На разных стадиях статистического исследования и моделирования возникает необходимость в формулировке и экспериментальной проверке некоторых предположений (гипотез) относительно природы и величины неизвестных параметров анализируемой генеральной совокупности (совокупностей). Например, исследователь высказывает предположение: "выборка извлечена из нормальной генеральной совокупности" или "генеральная средняя анализируемой совокупности равна пяти". Такие предположения называются статистическими гипотезами.
Сопоставление высказанной гипотезы относительно генеральной совокупности с имеющимися выборочными данными, сопровождаемое количественной оценкой степени достоверности получаемого вывода, осуществляется с помощью того или иного статистического критерия и называется проверкой статистических гипотез .
Выдвинутая гипотеза называется нулевой (основной) . Ее принято обозначать Н 0 .
По отношению к высказанной (основной) гипотезе всегда можно сформулировать альтернативную (конкурирующую) , противоречащую ей. Альтернативную (конкурирующую) гипотезу принято обозначать Н 1 .
Цель статистической проверки гипотез состоит в том, чтобы на основании выборочных данных принять решение о справедливости основной гипотезы Н 0 .
Если выдвигаемая гипотеза сводится к утверждению о том, что значение некоторого неизвестного параметра генеральной совокупности в точности равно заданной величине, то эта гипотеза называется простой , например: "среднедушевой совокупный доход населения России составляет 650 рублей в месяц"; "уровень безработицы (доля безработных в численности экономически активного населения) в России равна 9%" . В других случаях гипотеза называется сложной .
В качестве нулевой гипотезы Н 0 принято выдвигать простую гипотезу, т.к. обычно бывает удобнее проверять более строгое утверждение.
Гипотезы о виде закона распределения исследуемой случайной величины;
Гипотезы о числовых значениях параметров исследуемой генеральной совокупности;
Гипотезы об однородности двух или нескольких выборок или некоторых характеристик анализируемых совокупностей;
Гипотезы об общем виде модели, описывающей статистическую зависимость между признаками и др.
Так как проверка статистических гипотез осуществляется на основании выборочных данных, т.е. ограниченного ряда наблюдений, решения относительно нулевой гипотезы Н 0 имеют вероятностный характер. Другими словами, такое решение неизбежно сопровождается некоторой, хотя возможно и очень малой, вероятностью ошибочного заключения как в ту, так и в другую сторону.
Так, в какой-то небольшой доле случаев α нулевая гипотеза Н 0 может оказаться отвергнутой, в то время как в действительности в генеральной совокупности она является справедливой. Такую ошибку называют ошибкой первого рода . А ее вероятность принято называтьуровнем значимости и обозначать α .
Наоборот, в какой-то небольшой доле случаев β нулевая гипотеза Н 0 принимается, в то время как на самом деле в генеральной совокупности она ошибочна, а справедлива альтернативная гипотеза Н 1 . Такую ошибку называют ошибкой второго рода . Вероятность ошибки второго рода принято обозначать β . Вероятность 1 - β называют мощностью критерия .
При фиксированном объеме выборки можно выбрать по своему усмотрению величину вероятности только одной из ошибок α или β . Увеличение вероятности одной из них приводит к снижению другой. Принято задавать вероятность ошибки первого рода α - уровень значимости. Как правило, пользуются некоторыми стандартными значениями уровня значимости α : 0,1; 0,05; 0,025; 0,01; 0,005; 0,001. Тогда, очевидно, из двух критериев, характеризующихся одной и той же вероятностью α отклонить правильную в действительности гипотезу Н 0 , следует принять тот, который сопровождается меньшей ошибкой второго рода β , т.е. большей мощностью. Снижения вероятностей обеих ошибок α и β можно добиться путем увеличения объема выборки.
Правильное решение относительно нулевой гипотезы Н 0 также может быть двух видов:
Будет принята нулевая гипотеза Н 0 , тогда как и на самом деле в генеральной совокупности верна нулевая гипотеза Н 0 ; вероятность такого решения 1 - α;
Нулевая гипотеза Н 0 будет отклонена в пользу альтернативной Н 1, тогда как и на самом деле в генеральной совокупности нулевая гипотеза Н 0 отклоняется в пользу альтернативной Н 1 ; вероятность такого решения 1 - β - мощность критерия.
Результаты решения относительно нулевой гипотезы можно проиллюстрировать с помощью таблицы 8.1.
Таблица 8.1
Проверка статистических гипотез осуществляется с помощью статистического критерия (назовем его в общем виде К ), являющего функцией от результатов наблюдения.
Статистический критерий - это правило (формула), по которому определяется мера расхождения результатов выборочного наблюдения с высказанной гипотезой Н 0 .
Статистический критерий, как и всякая функция от результатов наблюдения, является случайной величиной и в предположении справедливости нулевой гипотезы Н 0 подчинена некоторому хорошо изученному (и затабулированному) теоретическому закону распределения с плотностью распределения f(k) .
Выбор критерия для проверки статистических гипотез может быть осуществлен на основании различных принципов. Чаще всего для этого пользуются принципом отношения правдоподобия , который позволяет построить критерий наиболее мощный среди всех возможных критериев. Суть его сводится к выбору такого критерия К с известной функцией плотности f(k) при условии справедливости гипотезы Н 0 , чтобы при заданном уровнем значимости α можно было бы найти критическую точку К кр .распределения f(k) , которая разделила бы область значений критерия на две части: область допустимых значений, в которой результаты выборочного наблюдения выглядят наиболее правдоподобными, и критическую область, в которой результаты выборочного наблюдения выглядят менее правдоподобными в отношении нулевой гипотезы Н 0 .
Если такой критерий К выбран, и известна плотность его распределения, то задача проверки статистической гипотезы сводится к тому, чтобы при заданном уровне значимости α рассчитать по выборочным данным наблюдаемое значение критерия К набл. и определить является ли оно наиболее или менее правдоподобным в отношении нулевой гипотезы Н 0 .
Проверка каждого типа статистических гипотез осуществляется с помощью соответствующего критерия, являющегося наиболее мощным в каждом конкретном случае. Например, проверка гипотезы о виде закона распределения случайной величины может быть осуществлена с помощью критерия согласия Пирсона χ 2 ; проверка гипотезы о равенстве неизвестных значений дисперсий двух генеральных совокупностей - с помощью критерия F - Фишера; ряд гипотез о неизвестных значениях параметров генеральных совокупностей проверяется с помощью критерия Z - нормальной распределенной случайной величины и критерия T - Стьюдента и т.д.
Значение критерия, рассчитываемое по специальным правилам на основании выборочных данных, называется наблюдаемым значением критерия (К набл. ).
Значения критерия, разделяющие совокупность значений критерия на область допустимых значений (наиболее правдоподобных в отношении нулевой гипотезы Н 0 ) и критическую область (область значений, менее правдоподобных в отношении таблицам распределения случайной величины К , выбранной в качестве критерия, называются критическими точками(К кр.).
Областью допустимых значений (областью принятия нулевой гипотезы Н 0) К Н 0 не отклоняется.
Критической областью называют совокупность значений критерия К , при которых нулевая гипотеза Н 0 отклоняется в пользу конкурирующей Н 1 .
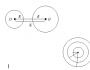
Различают одностороннюю (правостороннюю или левостороннюю) и двустороннюю критические области .
Если конкурирующая гипотеза - правосторонняя, например, Н 1: а > а 0 , то и критическая область - правосторонняя (рис 1). При правосторонней конкурирующей гипотезе критическая точка (К кр. правосторонняя) принимает положительные значения.
Если конкурирующая гипотеза - левосторонняя, например, Н 1: а < а 0 , то и критическая область - левосторонняя (рис 2). При левосторонней конкурирующей гипотезе критическая точка принимает отрицательные значения (К кр. левосторонняя) .
Если конкурирующая гипотеза - двусторонняя, например, Н 1: а ¹ а 0 , то и критическая область - двусторонняя (рис 3). При двусторонней конкурирующей гипотезе определяются две критические точки (К кр. левосторонняя и К кр. правосторонняя) .
Область допустимых Критическая
значений область