Простая линейная регрессия. Характеристики регрессионной модели
Парная (простая) линейная регрессия представляет собой модель, где среднее значение зависимой (объясняемой) переменной рассматривается как функция одной независимой (объясняющей) переменной x , т.е. это модель вида:
Так же y называют результативным признаком, а x признаком-фактором.
Знак «^» означает, что между переменными x и y нет строгой функциональной зависимости. Практически в каждом отдельном случае величина y складывается из двух слагаемых:
![]() (4.5)
(4.5)
где y – фактическое значение результативного признака;
– теоретическое значение результативного признака, найденное исходя из уравнения регрессии;
e – случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии.
Случайная величина e включает влияние не учтенных в модели факторов, случайных ошибок и особенностей измерения. Ее присутствие в модели порождено тремя источниками: спецификацией модели, выборочным характером исходных данных, особенностями измерения переменных.
Различают линейные и нелинейные регрессии.
Линейная регрессия: y = a + b × x + e .
Нелинейные регрессии делятся на два класса:
ü регрессии,нелинейныеотносительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам;
ü регрессии, нелинейные по оцениваемым параметрам.
Например:
ü регрессии, нелинейные по объясняющим переменным :
полиномы разных степеней y = a + b × x + b × x 2 + ... + b × x n + e ;
равностронняя гипербола y = a + b /x + e ;
ü регрессии, нелинейные по оцениваемым параметрам :
степенная y = a × x b × e ;
Показательная y = a × b x ×e ;
Экспоненциальная y = e a + bx +e .
Построение уравнения регрессии сводится к оценке ее параметров. Для оценки параметров регрессий, линейных по параметрам, используют метод наименьших квадратов (МНК). МНК позволяет получить такиеоценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака y от теоретических минимальна, т.е.
![]() (4.6)
(4.6)
Для линейных и нелинейных уравнений, приводимых к линейным, решается следующая система относительно a и b :
 (4.7)
(4.7)
Можно воспользоваться готовыми формулами, которые вытекают непосредственно из решения этой системы:
 (4.8)
(4.8)
где – ковариация признаков x и y,
– дисперсия признака x и
(Ковариация – числовая характеристика совместного распределения двух случайных величин, равная математическому ожиданию произведения отклонений этих случайных величин от их математических ожиданий. Дисперсия – характеристика случайной величины, определяемая как математическое ожидание квадрата отклонения случайной величины от ее математического ожидания. Математическое ожидание – сумма произведений значений случайной величины на соответствующие вероятности.)
Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции r xy для линейной регрессии(-1£ r xy £1):
 (4.9)
(4.9)
и индекс корреляции r xy – для нелинейной регрессии(0£ r xy £ 1):
 (4.10)
(4.10)
где ![]() –
общая дисперсия результативного признака у
;
–
общая дисперсия результативного признака у
;
![]() –
остаточная дисперсия, определяемая исходя из уравнения регрессии
–
остаточная дисперсия, определяемая исходя из уравнения регрессии
Оценку качества построенной модели даст коэффициент (индекс) детерминации r 2 (для линейной регрессии) либо r 2 (для нелинейной регрессии), а также средняя ошибка аппроксимации.
Средняя ошибка аппроксимации – среднее отклонение расчетных значений от фактических:
 (4.11)
(4.11)
Допустимый предел значений – не более 10%.
Средний коэффициент эластичности показывает, на сколько процентов в среднем по совокупности изменится результат у от своей средней величины при изменении фактора x на1%от своего среднего значения:
![]() (4.12)
(4.12)
После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом,так и отдельных егопараметров.
Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Оценка значимости уравнения регрессии в целом производится на основе F -критерия Фишера , которому предшествует дисперсионный анализ. Согласно основной идее дисперсионного анализа, общая сумма квадратов отклонений переменной y от среднего значения y раскладывается на две части – « объясненную » и «необъясненную »:
где ∑(y - ) 2 – общая сумма квадратов отклонений;
( - ) 2 – сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений);
∑(y – ) 2 – остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов.
Схема дисперсионного анализа имеет вид, представленный в табл. 4.1 (n – число наблюдений, m – число параметров при переменной x ).
Таблица 4.1

Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду (напомним, что степени свободы – это числа, показывающие количество элементов варьирования, которые могут принимать произвольные значения, не изменяющие заданных характеристик). Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F -критерия Фишера:
Фактическое значение F -критерия Фишера сравнивается с табличным значением F табл (a ; k 1 ; k 2) при уровне значимости a и степенях свободы k 1 = m и k 2 = n - m - 1. При этом, если фактическое значение F -критерия больше табличного, то признается статистическая значимость уравнения в целом.
Для парной линейной регрессии m = 1, поэтому
 (4.15)
(4.15)
Величина F -критерия связана с коэффициентом детерминации r xy 2 , и ее можно рассчитать по следующей формуле:
 (4.16)
(4.16)
Для оценки статистической значимости параметров регрессии и корреляции рассчитываются t -критерий Стьюдента и доверительные интервалы каждого из показателей.Оценка значимости коэффициентоврегрессии и корреляции с помощью t -критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки:
 (4.17)
(4.17)
Стандартные ошибки параметров линейной регрессии икоэффициента корреляции определяются по формулам:
|

Сравнивая фактическое и критическое (табличное) значения t - статистики – t табл и t факт – делаем вывод о значимости параметров регрессии и корреляции. Если t табл < t факт то параметры a , b и r xy не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора x. Если t табл > t факт , то признается случайная природа формирования a , b или r xy .
Для расчета доверительного интервала определяем предельную ошибку ∆для каждого показателя:
Формулы для расчета доверительных интервалов имеют следующий вид:

Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, так как он не может одновременно принимать и положительное, и отрицательное значения.
Связь между F -критерием Фишера и t -статистикой Стьюдента выражается равенством
![]()
В прогнозных расчетах по уравнению регрессии определяется предсказываемое индивидуальное значение y 0 как точечный прогноз при x = x 0 ,т.е.путем подстановки в линейное уравнение = a + b × x соответствующего значения x. Однако точечный прогноз явно нереален, поэтому он дополняется расчетом стандартной ошибки
 (4.19)
(4.19)
где  , и построением доверительного интервала
прогнозного значения :
, и построением доверительного интервала
прогнозного значения :
C помощью инструмента анализа данных Регрессия можно получить результаты регрессионной статистики, дисперсионного анализа, доверительных интервалов, остатки и графики подбора линии регрессии.
Если в меню сервис еще нет команды Анализ данных , то необходимо сделать следующее. В главном меню последовательно выбираем Сервис→Надстройки и устанавливаем «флажок» в строке Пакет анализа (рис. 4.1).
1. Если исходные данные уже внесены, то выбираем Сервис→Анализ данных→Регрессия .
2. Заполняем диалоговое окно ввода данных и параметров вывода (рис. 4.2).
Входной интервал Y –диапазон,содержащий данныерезультативного признака;
Входной интервал X –диапазон,содержащий данные признака-фактора;
Метки – «флажок»,который указывает,содержит ли первая строканазвания столбцов;
Рис. 4.1. Строка Пакет анализа
Рис. 4.2. Диалоговое окно ввода данных и параметров вывода
Константа – ноль – «флажок»,указывающий на наличие илиотсутствие свободного члена в уравнении;
Выходной интервал –достаточно указать левую верхнюю ячейкубудущего диапазона;
Новый рабочий лист –можно указать произвольное имя новоголиста (или не указывать, тогда результаты выводятся на вновь созданный лист).
Получаем подобные результаты:
Откуда выписываем, округляя до 4 знаков после запятой и переходя к нашим обозначениям:
Уравнение регрессии:
76,9765+0,9204x .
Коэффициент корреляции:
r xy =0,7210.
Коэффициент детерминации:
r xy 2 =0,5199.
Фактическое значение F -критерия Фишера:
F =10,8280
Остаточная дисперсия на одну степень свободы:
S ост 2 =157, 4922.
Корень квадратный из остаточной дисперсии (стандартная ошибка):
S ост =12,5496.
Стандартные ошибки для параметров регрессии:
m a =24, 2116 , m b =0, 2797.
Фактические значения t -критерия Стьюдента:
t a =3,1793, t b =3,2906.
Доверительные интервалы:
23,0298 £ a * £130,9232,
0,2972 £ b * £ ,5437.
Как видим, найдены все рассмотренные выше параметры и характеристики уравнения регрессии, за исключением средней ошибки аппроксимации (значение t -критерия Стьюдента для коэффициента корреляции совпадает с t b ). Результаты «ручного счета» от машинного отличаются незначительно (отличия связаны с ошибками округления).
4.3. Финансовое моделирование в Excel.
Начиная создавать финансовую модель предприятия, лучше руководствоваться принципом «от простого к сложному», иначе в попытке учесть все нюансы есть риск запутаться в большом количестве формул и ссылок. Поэтому вполне оправдано вначале создать простейшую модель (с минимальным количеством элементов), установить связи общего характера между внешними параметрами (спрос на продукцию, стоимость ресурсов) и внутренними показателями деятельности предприятия (выручка, затраты, денежные потоки и т. д.). В первой итерации можно не заботиться об особой точности задаваемых параметров. На этом этапе важнее установить правильные взаимосвязи между переменными так, чтобы финансовая модель предприятия автоматически пересчитывалась после изменения исходных данных и позволяла выстраивать различные сценарии. Уже после этого можно приступить к ее развитию, детализовать показатели, ввести дополнительные уровни аналитики и т. д.
1) Доходы. Построение финансовой модели в Excel начинается с задания внешних параметров. Отправной точкой для дальнейших расчетов послужит план продаж. ля этого в Excel на одном из листов книги размещается таблица с планом продаж в денежном выражении (табл. 4.1). На этом этапе выручку можно указать «навскидку» или использовать данные прошлого года. Пока точность не имеет большого значения. Позднее при детализации модели план продаж придется доработать.
2) Расходы. Исходя из объема продаж, определяется размер переменных затрат. В самом общем виде расчет может выглядеть следующим образом:
Переменные затраты = Доля в выручке х Объем продаж
Сделаем небольшое допущение и предположим, что в примере переменными являются только затраты на оплату труда – заработная плата сотрудников полностью зависит от объема оказанных услуг, на нее уходит примерно 30 процентов выручки от реализации. Кстати, план затрат удобнее разместить на отдельном листе Excel (табл. 4.2). В нем зарплата рассчитывается помесячно как произведение коэффициента 0,3 (30% / 100%) и плана продаж на определенный месяц. Расходы на аренду и управление вводятся на первом этапе создания финансовой модели предприятия не как расчетные величины, а как фиксированные значения. В дальнейшем при детализации модели их можно будет заменить формулами, увязав с другими показателями.
Таблица 4.1
План продаж в финансовой модели предприятия, тыс. руб.

Таблица 4.2
План затрат в финансовой модели предприятия, тыс. руб.

Не стоит перегружать планы верхнего уровня (баланс, прибыли и убытки, движение денежных средств) показателями. Лучше стремиться к тому, чтобы каждый из них мог уместиться на одном печатном листе. Зачастую трудно удержаться от соблазна расшифровать каждую цифру (например, в плане доходов и расходов расписать выручку по видам продукции, группам клиентов, каналам сбыта и т. п.). Если в план доходов и расходов включить сотню видов готовой продукции и статей затрат, это значительно затруднит его восприятие. Тем не менее с точки зрения информативности полезно подобные планы дополнять различными относительными показателями (например, в баланс внести показатели структуры активов и пассивов (удельные веса статей в валюте баланса), в план доходов и расходов – рентабельность).
В плане доходов и расходов (табл. 4.3) строки «Операционные расходы» и «Операционные доходы» заполняются при помощи ссылок на соответствующие ячейки функциональных планов. Выручка расшифрована по видам услуг, затраты – по статьям. В этом случае такая расшифровка допустима, поскольку не утяжеляет восприятие отчета и не усложняет его анализ. Кроме того, в отчет включены два аналитических показателя – рентабельность (как отношение прибыли к выручке) и прибыль нарастающим итогом. Если понадобится провести более глубокий анализ, в частности, динамики доли оплаты труда в себестоимости услуг, все необходимые для этого расчеты лучше проводить на отдельном листе.
Таблица 4.3
План доходов и расходов в финансовой модели предприятия, тыс. руб.

План движения денежных средств (табл. 4.4) в нашем примере формируется со следующими допущениями.
Таблица 4.4
План движения денежных средств, тыс. руб.

Первое: разделы «Финансовая деятельность» и «Инвестиционная деятельность» исключены из плана. Предполагается, что предприятие осуществляет только операционную деятельность, не привлекая заемные средства и не осуществляя капитальные вложения. Еще одно допущение. Предприятие оказывает услуги физическим лицам за наличный расчет, а значит, время оказания услуги и ее оплаты совпадает – в итоге у предприятия нет дебиторской задолженности. Ситуация с платежами по операционной деятельности не так однозначна. Зарплата и аренда выплачиваются в месяце, следующем за месяцем начисления, а управленческие расходы – в месяце их осуществления.Последнее, что остается сделать, – создать прогнозный баланс (табл. 4.5). Данные по оборотам за период берутся из ПДР и ПДДС, начальные остатки – из баланса за предыдущий период (здесь допустимо ручное внесение информации).
Таблица 4.5
Прогнозный баланс, тыс. руб.

Построенная таким образом финансовая модель обозначает основные группы показателей, характеризующих деятельность предприятия (доходы, расходы, денежные средства и т. п.), увязывает их в три сводных плана. Даже эту простейшую на первый взгляд модель можно использовать для сценарного анализа. В частности, если исключить из плана продаж услугу № 1(соответствующую строку удалять не нужно, достаточно проставить по ней нули), то можно увидеть, насколько ухудшатся показатели рентабельности и ликвидности.
Чтобы превратить модель в полноценный инструмент сценарного анализа, потребуется «насытить» ее аналитикой, детализировать исходную информацию до показателей, которыми можно управлять на практике. Например, в случае с предприятием, оказывающим услуги, очевидна необходимость детализации плана продаж, внесенного ранее в модель в денежном выражении. Выручку по каждому виду услуг можно рассчитать как произведение цены единицы услуги и количества указанных услуг. На практике, естественно, план продаж формируется исходя из конъюнктуры рынка, ожидаемого спроса, предполагаемой цены реализации, достигнутых договоренностей с ключевыми клиентами, запланированных маркетинговых мероприятий, ценовой и кредитной политики и т. д.
Аналогично детализируются и другие исходные данные. Например, арендную плату можно было бы разложить на площадь арендуемого помещения и стоимость одного квадратного метра, зарплату расписать по сотрудникам, управленческие расходы разбить по видам. В итоге функциональность финансовой модели предприятия развивается до такого уровня, что можно увидеть, как влияет изменение любого, даже самого незначительного параметра на конечный результат.
Сверстать подробную финансовую модель предприятия – задача интересная, но сложная. Потребуется скрупулезно изучить и адекватно математически описать существующие взаимосвязи как внутрипроизводственных процессов, так и внешних факторов. Силами одной финансовой службы такую модель не сделать, понадобится участие всех служб предприятия – от департамента продаж до бухгалтерии.
Использование финансовой модели при планировании деятельности помогает увидеть, как те или иные планы развития отражаются на структуре активов, пассивов, доходов и расходов предприятия, а также определить, от каких факторов в наибольшей степени зависят будущая прибыль, ликвидность и финансовая устойчивость. Модель служит скорее инструментом мониторинга текущей ситуации на предприятии и выработки адекватной финансовой политики.
Финансовую модель предприятия стоит использовать в процессе бюджетирования сразу же после утверждения плана продаж. Если план продаж «прогнать» через модель, то полученный финансовый результат можно показать акционерам, чтобы установить целевые значения по затратам, прибыли, дивидендам. Если планируемая выручка не обеспечивает необходимой прибыли с точки зрения акционеров, прямо в модели корректируются влияющие показатели. Окончательный вариант расчетов модели определяет целевые значения бюджетных лимитов для всех центров финансовой ответственности. В течение года финансовую модель предпредприятия можно будет корректировать, проставлять по пройденным месяцам фактические данные вместо плановых и контролировать таким образом финансовые результаты, отслеживать негативные тенденции и четко понимать, к чему они приведут предприятие.
Финансовая модель в Excel дает возможность:
Спланировать деятельность по проекту, внести ясность в соотношение его эффективности и планируемых затрат на его реализацию;
Проанализировать финансовые показатели проекта, такие как как NPV, IRR, PBP, WACC и др.;
Вводить и анализировать любые изменения в проект.
К преимуществам использования моделирования в Excel относится то, что получаемая финансовая модель гибка и понятна. Вы с любой момент можете посмотреть формулу расчета того или иного показателя и изменять исходные данные проекта по своему усмотрению. Еще одно преимущество построения финансовой модели в Excel - то, что все расчеты идут последовательно и обоснованно.
Для построения финансовой модели в Excel необходима следующая информация по проекту:
Баланс компании на последнюю отчетную дату;
Список продуктов, цены, объем продаж, способы оплаты;
Перечень издержек компании, таких как прямые и общие издержки, заработная плата персонала;
Условия финансирования;
Инвестиционный план проекта;
Условия лизинга (если имеется).
Выходами финансовой модели в Excel являются:
Отчет о прибыли и убытках;
Отчет о движении денежных средств;
Финансовые показатели проекта.
Что такое регрессия?
Рассмотрим две непрерывные переменные x=(x 1 , x 2 , .., x n), y=(y 1 , y 2 , ..., y n).
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение
, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x , причём изменения в y вызываются именно изменениями в x , мы можем определить линию регрессии (регрессия y на x ), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова "регрессия" исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей "регрессировал" и "двигался вспять" к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x
называется независимой переменной или предиктором.
Y - зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x , т.е. это «предсказанное значение y »
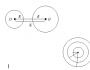
- a - свободный член (пересечение) линии оценки; это значение Y , когда x=0 (Рис.1).
- b - угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b .
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия .
Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a
и b
- выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a
и b
является метод наименьших квадратов
(МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y
- предсказанный y
, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины остаток равен разнице и соответствующего предсказанного Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Остатки нормально распределены с нулевым средним значением;
Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
"Влиятельное" наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть "влиятельным" наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для "влиятельных" наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению , которая подчиняется распределению с степенями свободы, где стандартная ошибка коэффициента

 ,
,
 - оценка дисперсии остатков.
- оценка дисперсии остатков.
Обычно если достигнутый уровень значимости нулевая гипотеза отклоняется.
![]()
где процентная точка распределения со степенями свободы что дает вероятность двустороннего критерия
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем, мы можем аппроксимировать значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется
, и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации , обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение путем подстановки этого значения в уравнение линии регрессии.
Итак, если прогнозируем как Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Y = b0 + b1 P
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b0 + b1 P2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 (Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 (Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на.40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p<.05 . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на.65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся "внутри диапазона."

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию (-.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p<.001 .
Итог
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Пусть определен характер экспериментальных данных и выделен определенный набор объясняющих переменных.
Для того, чтобы найти объясненную часть, т. е. величину М Х (У), требуется знание условных распределений случайной величины Y. На практике это почти никогда не имеет места, поэтому точное нахождение объясненной части невозможно.
В таких случаях применяется стандартная процедура сглаживания экспериментальных данных, подробно описанная, например, в . Эта процедура состоит из двух этапов:
- 1) определяется параметрическое семейство, к которому принадлежит искомая функция М х (Y) (рассматриваемая как функция от значений объясняющих переменных X). Это может быть множество линейных функций, показательных функций и т.д.;
- 2) находятся оценки параметров этой функции с помошыо одного из методов математической статистики.
Формально никаких способов выбора параметрического семейства не существует. Однако в подавляющем большинстве случаев эконометрические модели выбираются линейными.
Кроме вполне очевидного преимущества линейной модели - ее относительной простоты , - для такого выбора имеются, по крайней мере, две существенные причины.
Первая причина: если случайная величина (X, Y) имеет совместное нормальное распределение, то, как известно, уравнения регрессии линейные (см. § 2.5). Предположение о нормальном распределении является вполне естественным и в ряде случаев может быть обосновано с помощью предельных теорем теории вероятностей (см. § 2.6).
В других случаях сами величины Y или X могут не иметь нормального распределения, но некоторые функции от них распределены нормально. Например, известно, что логарифм доходов населения - нормально распределенная случайная величина. Вполне естественно считать нормально распределенной случайной величиной пробег автомобиля. Часто гипотеза о нормальном распределении принимается во многих случаях, когда нет явного ей противоречия, и, как показывает практика, подобная предпосылка оказывается вполне разумной.
Вторая причина, по которой линейная регрессионная модель оказывается предпочтительнее других, - это меньший риск значительной ошибки прогноза.
Рис. 1.1 иллюстрирует два выбора функции регрессии - линейной и квадратичной. Как видно, имеющееся множество экспериментальных данных (точек) парабола сглаживает, пожалуй, даже лучше, чем прямая. Однако парабола быстро удаляется от корреляционного поля и для добавленного наблюдения (обозначенного крестиком) теоретическое значение может очень значительно отличаться от эмпирического.
Можно придать точный математический смысл этому утверждению: ожидаемое значение ошибки прогноза , т.е. математическое ожидание квадрата отклонения наблюдаемых значений от сглаженных (или теоретических) М (К на б Л - ^теор) 2 оказывается меньше в том случае, если уравнение регрессии выбрано линейным.
В настоящем учебнике мы в основном будем рассматривать линейные регрессионные модели, и, по мнению авторов, это вполне соответствует той роли, которую играют линейные модели в эконометрике.
Наиболее хорошо изучены линейные регрессионные модели, удовлетворяющие условиям (1.6), (1.7) и свойству постоянства дисперсии ошибок регрессии, - они называются /иассическими моделями.
Заметим, что условиям классической регрессионной модели удовлетворяют и гомоскедастичная модель пространственной выборки, и модель временного ряда, наблюдения которого не коррелируют, а дисперсии постоянны. С математической точки зрения они действительно неразличимы (хотя могут значительно различаться экономические интерпретации полученных математических результатов).
Подробному рассмотрению классической регрессионной модели посвящены гл. 3, 4 настоящего учебника. Практически весь последующий материал посвящен моделям, которые так или иначе могут быть сведены к классической. Часто раздел эконометрики, изучающий классические регрессионные модели, называется «Эконометрикой-1», в то время как курс «Эконометрика-2» охватывает более сложные вопросы, связанные с временными рядами, а также более сложными, существенно нелинейными моделями.
Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения, линейная регрессия остается одним из популярных инструментов. И для этого есть свои предпосылки, не последнее месте среди которых занимает интуитивность в интерпретации модели.
Немного формул
В простейшем случае линейную модель можно представить так:Y i = a 0 + a 1 x i + ε i
Где a 0 - математическое ожидание зависимой переменной y i , когда переменная x i равна нулю; a 1 - ожидаемое изменение зависимой переменной y i при изменении x i на единицу (этот коэффициент подбирают таким образом, чтобы величина ½Σ(y i -ŷ i) 2 была минимальна - это так называемая «функция невязки»); ε i - случайная ошибка.
При этом коэффициенты a 1 и a 0 можно выразить через матан коэффициент корреляции Пирсона , стандартные отклонения и средние значения переменных x и y:
 1 = cor(y, x)σ y /σ x
 0 = ȳ - â 1 x̄
Диагностика и ошибки модели
Чтобы модель была корректной, необходимо выполнение условий Гаусса-Маркова , т.е. ошибки должны быть гомоскедастичны с нулевым математическим ожиданием. График остатков e i = y i - ŷ i помогает определить, насколько адекватна построенная модель (e i можно считать оценкой ε i).Посмотрим на график остатков в случае простой линейной зависимости y 1 ~ x (здесь и далее все примеры приводятся на языке R ):
Скрытый текст
set.seed(1)
n <- 100
x <- runif(n)
y1 <- x + rnorm(n, sd=.1)
fit1 <- lm(y1 ~ x)
par(mfrow=c(1, 2))
plot(x, y1, pch=21, col="black", bg="lightblue", cex=.9)
abline(fit1)
plot(x, resid(fit1), pch=21, col="black", bg="lightblue", cex=.9)
abline(h=0)

Остатки более-менее равномерно распределены относительно горизонтальной оси, что говорит об «отсутствие систематической связи между значениями случайного члена в любых двух наблюдениях». А теперь исследуем такой же график, но построенный для линейной модели, которая на самом деле не является линейной:
Скрытый текст
y2 <- log(x) + rnorm(n, sd=.1)
fit2 <- lm(y2 ~ x)
plot(x, y2, pch=21, col="black", bg="lightblue", cex=.9)
abline(fit2)
plot(x, resid(fit2), pch=21, col="black", bg="lightblue", cex=.9)
abline(h=0)

По графику y 2 ~ x вроде бы можно предположить линейную зависимость, но у остатков есть паттерн, а значит, чистая линейная регрессия тут не пройдет . А вот что на самом деле означает гетероскедастичность :
Скрытый текст
y3 <- x + rnorm(n, sd=.001*x)
fit3 <- lm(y3 ~ x)
plot(x, y3, pch=21, col="black", bg="lightblue", cex=.9)
abline(fit3)
plot(x, resid(fit3), pch=21, col="black", bg="lightblue", cex=.9)
abline(h=0)

Линейная модель с такими «раздувающимися» остатками не корректна. Еще иногда бывает полезно построить график квантилей остатков против квантилей, которые можно было бы ожидать при условии, что остатки нормально распределены:
Скрытый текст
qqnorm(resid(fit1))
qqline(resid(fit1))
qqnorm(resid(fit2))
qqline(resid(fit2))

На втором графике четко видно, что предположение о нормальности остатков можно отвергнуть (что опять таки говорит о некорректности модели). А еще бывают такие ситуации:
Скрытый текст
x4 <- c(9, x)
y4 <- c(3, x + rnorm(n, sd=.1))
fit4 <- lm(y4 ~ x4)
par(mfrow=c(1, 1))
plot(x4, y4, pch=21, col="black", bg="lightblue", cex=.9)
abline(fit4)

Это так называемый «выброс» , который может сильно исказить результаты и привести к ошибочным выводам. В R есть средства для его обнаружения - с помощью стандартизованой меры dfbetas и hat values :
> round(dfbetas(fit4), 3) (Intercept) x4 1 15.987 -26.342 2 -0.131 0.062 3 -0.049 0.017 4 0.083 0.000 5 0.023 0.037 6 -0.245 0.131 7 0.055 0.084 8 0.027 0.055 .....
> round(hatvalues(fit4), 3) 1 2 3 4 5 6 7 8 9 10... 0.810 0.012 0.011 0.010 0.013 0.014 0.013 0.014 0.010 0.010...
Как видно, первый член вектора x4 оказывает заметно большее влияние на параметры регрессионной модели, нежели остальные, являясь, таким образом, выбросом.
Выбор модели при множественной регрессии
Естественно, что при множественной регрессии возникает вопрос: стоит ли учитывать все переменные? С одной стороны, казалось бы, что стоит, т.к. любая переменная потенциально несет полезную информацию. Кроме того, увеличивая количество переменных, мы увеличиваем и R 2 (кстати, именно по этой причине эту меру нельзя считать надежной при оценке качества модели). С другой стороны, стоить помнить о таких вещах, как AIC и BIC , которые вводят штрафы за сложность модели. Абсолютное значение информационного критерия само по себе не имеет смысла, поэтому надо сравнивать эти значения у нескольких моделей: в нашем случае - с разным количеством переменных. Модель с минимальным значением информационного критерия будет наилучшей (хотя тут есть о чем поспорить).Рассмотрим датасет UScrime из библиотеки MASS:
library(MASS) data(UScrime) stepAIC(lm(y~., data=UScrime))
Модель с наименьшим значением AIC имеет следующие параметры:
Call: lm(formula = y ~ M + Ed + Po1 + M.F + U1 + U2 + Ineq + Prob, data = UScrime) Coefficients: (Intercept) M Ed Po1 M.F U1 U2 Ineq Prob -6426.101 9.332 18.012 10.265 2.234 -6.087 18.735 6.133 -3796.032
Таким образом, оптимальная модель с учетом AIC будет такой:
fit_aic <- lm(y ~ M + Ed + Po1 + M.F + U1 + U2 + Ineq + Prob, data=UScrime) summary(fit_aic)
... Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -6426.101 1194.611 -5.379 4.04e-06 *** M 9.332 3.350 2.786 0.00828 ** Ed 18.012 5.275 3.414 0.00153 ** Po1 10.265 1.552 6.613 8.26e-08 *** M.F 2.234 1.360 1.642 0.10874 U1 -6.087 3.339 -1.823 0.07622 . U2 18.735 7.248 2.585 0.01371 * Ineq 6.133 1.396 4.394 8.63e-05 *** Prob -3796.032 1490.646 -2.547 0.01505 * Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Если внимательно присмотреться, то окажется, что у переменных M.F и U1 довольно высокое значение p-value, что как бы намекает нам, что эти переменные не так уж и важны. Но p-value - довольно неоднозначная мера при оценки важности той или иной переменной для статистической модели. Наглядно этот факт демонстрирует пример:
data <- read.table("http://www4.stat.ncsu.edu/~stefanski/NSF_Supported/Hidden_Images/orly_owl_files/orly_owl_Lin_9p_5_flat.txt") fit <- lm(V1~. -1, data=data) summary(fit)$coef
Estimate Std. Error t value Pr(>|t|) V2 1.1912939 0.1401286 8.501431 3.325404e-17 V3 0.9354776 0.1271192 7.359057 2.568432e-13 V4 0.9311644 0.1240912 7.503873 8.816818e-14 V5 1.1644978 0.1385375 8.405652 7.370156e-17 V6 1.0613459 0.1317248 8.057300 1.242584e-15 V7 1.0092041 0.1287784 7.836752 7.021785e-15 V8 0.9307010 0.1219609 7.631143 3.391212e-14 V9 0.8624487 0.1198499 7.196073 8.362082e-13 V10 0.9763194 0.0879140 11.105393 6.027585e-28
p-values у каждой переменной - практически нуль, и можно предположить, что все переменные важны для этой линейной модели. Но на самом деле, если присмотреться к остаткам, выходит как-то так:
Скрытый текст
plot(predict(fit), resid(fit), pch=".")

И все же, альтернативный подход основывается на дисперсионном анализе , в котором значения p-value играют ключевую роль. Сравним модель без переменной M.F с моделью, построенной с учетом только AIС:
fit_aic0 <- update(fit_aic, ~ . - M.F) anova(fit_aic0, fit_aic)
Analysis of Variance Table Model 1: y ~ M + Ed + Po1 + U1 + U2 + Ineq + Prob Model 2: y ~ M + Ed + Po1 + M.F + U1 + U2 + Ineq + Prob Res.Df RSS Df Sum of Sq F Pr(>F) 1 39 1556227 2 38 1453068 1 103159 2.6978 0.1087
Учитывая P-значение, равное 0.1087, при уровне значимости α=0.05 мы можем сделать вывод, что нет статистически значимого свидетельства в пользу альтернативной гипотезы, т.е. в пользу модели с дополнительной переменной M.F.
25.07.16 Ирина Аничина
51850 0
В данной статье мы поговорим о том, как понять, качественную ли модель мы построили. Ведь именно качественная модель даст нам качественные прогнозы.
Prognoz Platform обладает обширным списком моделей для построения и анализа. Каждая модель имеет свою специфику и применяется при различных предпосылках.
Объект «Модель» позволяет построить следующие регрессионные модели:
- Линейная регрессия (оценка методом наименьших квадратов);
- Линейная регрессия (оценка методом инструментальных переменных);
- Модель бинарного выбора (оценка методом максимального правдоподобия);
- Нелинейная регрессия (оценка нелинейным методом наименьших квадратов).
Начнём с модели линейной регрессии. Многое из сказанного будет распространяться и на другие виды.
Модель линейной регрессии (оценка МНК)
где y – объясняемый ряд, x 1 , …, x k – объясняющие ряды, e – вектор ошибок модели, b 0 , b 1 , …, b k – коэффициенты модели.
Итак, куда смотреть?
Коэффициенты модели
Для каждого коэффициента на панели «Идентифицированное уравнение» вычисляется ряд статистик: стандартная ошибка, t -статистика , вероятность значимости коэффициента . Последняя является наиболее универсальной и показывает, с какой вероятностью удаление из модели фактора, соответствующего данному коэффициенту, не окажется значимым.
Открываем панель и смотрим на последний столбец, ведь он – именно тот, кто сразу же скажет нам о значимости коэффициентов.

Факторов с большой вероятностью незначимости в модели быть не должно.

Как вы видите, при исключении последнего фактора коэффициенты модели практически не изменились.
Возможные проблемы: Что делать, если согласно вашей теоретической модели фактор с большой вероятностью незначимости обязательно должен быть? Существуют и другие способы определения значимости коэффициентов. Например, взгляните на матрицу корреляции факторов.
Матрица корреляции
Панель «Корреляция факторов» содержит матрицу корреляции между всеми переменными модели, а также строит облако наблюдений для выделенной пары значений.

Коэффициент корреляции показывает силу линейной зависимости между двумя переменными. Он изменяется от -1 до 1. Близость к -1 говорит об отрицательной линейной зависимости, близость к 1 – о положительной.
Облако наблюдений позволяет визуально определить, похожа ли зависимость одной переменной от другой на линейную.
Если среди факторов встречаются сильно коррелирующие между собой, исключите один из них. При желании вместо модели обычной линейной регрессии вы можете построить модель с инструментальными переменными, включив в список инструментальных исключённые из-за корреляции факторы.
Матрица корреляции не имеет смысла для модели нелинейной регрессии, поскольку она показывает только силу линейной зависимости.
Критерии качества
Помимо проверки каждого коэффициента модели важно знать, насколько она хороша в целом. Для этого вычисляют статистики, расположенные на панели «Статистические характеристики».
Коэффициент детерминации (R 2 ) – наиболее распространённая статистика для оценки качества модели. R 2 рассчитывается по следующей формуле:

где n
– число наблюдений; y i
— значения объясняемой переменной; ![]() — среднее значение объясняемой переменной; ỹ
i
— модельные значения, построенные по оцененным параметрам.
— среднее значение объясняемой переменной; ỹ
i
— модельные значения, построенные по оцененным параметрам.
R 2 принимает значение от 0 до 1 и показывает долю объяснённой дисперсии объясняемого ряда. Чем ближе R 2 к 1, тем лучше модель, тем меньше доля необъяснённого.
Возможные проблемы: Проблемы с использованием R 2 заключаются в том, что его значение не уменьшается при добавлении в уравнение факторов, сколь плохи бы они ни были. Он гарантированно будет равен 1, если мы добавим в модель столько факторов, сколько у нас наблюдений. Поэтому сравнивать модели с разным количеством факторов, используя R 2 , не имеет смысла.
Для более адекватной оценки модели используется скорректированный коэффициент детерминации (Adj R 2 ) . Как видно из названия, этот показатель представляет собой скорректированную версию R 2 , накладывая «штраф» за каждый добавленный фактор:

где k – число факторов, включенных в модель.
Коэффициент Adj R 2 также принимает значения от 0 до 1, но никогда не будет больше, чем значение R 2 .
Аналогом t -статистики коэффициента является статистика Фишера (F -статистика) . Однако если t -статистика проверяет гипотезу о незначимости одного коэффициента, то F -статистика проверяет гипотезу о том, что все факторы (кроме константы) являются незначимыми. Значение F -статистики также сравнивают с критическим, и для него мы также можем получить вероятность незначимости. Стоит понимать, что данный тест проверяет гипотезу о том, что все факторы одновременно являются незначимыми. Поэтому при наличии незначимых факторов модель в целом может быть значима.
Возможные проблемы: Большинство статистик строится для случая, когда модель включает в себя константу. Однако в Prognoz Platform мы имеем возможность убрать константу из списка оцениваемых коэффициентов. Стоит понимать, что такие манипуляции приводят к тому, что некоторые характеристики могут принимать недопустимые значения. Так, R 2 и Adj R 2 при отсутствии константы могут принимать отрицательные значения. В таком случае их уже не получится интерпретировать как долю, принимающую значение от 0 до 1.
Для моделей без константы в Prognoz Platform рассчитываются нецентрированные коэффициенты детерминации (R 2 и Adj R 2 ). Модифицированная формула приводит их значения к диапазону от 0 до 1 даже в модели без константы.
Посмотрим значения описанных критериев для приведённой выше модели:

Как мы видим, коэффициент детерминации достаточно велик, однако есть ещё значительная доля необъяснённой дисперсии. Статистика Фишера говорит о том, что выбранная нами совокупность факторов является значимой.
Сравнительные критерии
Кроме критериев, позволяющих говорить о качестве модели самой по себе, существует ряд характеристик, позволяющих сравнивать модели друг с другом (при условии, что мы объясняем один и тот же ряд на одном и том же периоде).
Большинство моделей регрессии сводятся к задаче минимизации суммы квадратов остатков (sum of squared residuals , SSR ) . Таким образом, сравнивая модели по этому показателю, можно определить, какая из моделей лучше объяснила исследуемый ряд. Такой модели будет соответствовать наименьшее значение суммы квадратов остатков.
Возможные проблемы: Стоит заметить, что с ростом числа факторов данный показатель так же, как и R 2 , будет стремиться к граничному значению (у SSR, очевидно, граничное значение 0).
Некоторые модели сводятся к максимизации логарифма функции максимального правдоподобия (LogL ) . Для модели линейной регрессии эти задачи приводят к одинаковому решению. На основе LogL строятся информационные критерии, часто используемые для решения задачи выбора как регрессионных моделей, так и моделей сглаживания:
- информационный критерий Акаике (Akaike Information criterion , AIC )
- критерий Шварца (Schwarz Criterion , SC )
- критерий Ханнана-Куина (Hannan - Quinn Criterion , HQ )
Все критерии учитывают число наблюдений и число параметров модели и отличаются друг от друга видом «функции штрафа» за число параметров. Для информационных критериев действует правило: наилучшая модель имеет наименьшее значение критерия.

Сравним нашу модель с её первым вариантом (с «лишним» коэффициентом):

Как можно увидеть, данная модель хоть и дала меньшую сумму квадратов остатков, оказалась хуже по информационным критериям и по скорректированному коэффициенту детерминации.
Анализ остатков
Модель считается качественной, если остатки модели не коррелируют между собой. В противном случае имеет место постоянное однонаправленное воздействие на объясняемую переменную не учтённых в модели факторов. Это влияет на качество оценок модели, делая их неэффективными.
Для проверки остатков на автокорреляцию первого порядка (зависимость текущего значения от предыдущих) используется статистика Дарбина-Уотсона (DW ) . Её значение находится в промежутке от 0 до 4. В случае отсутствия автокорреляции DW близка к 2. Близость к 0 говорит о положительной автокорреляции, к 4 — об отрицательной.

Как оказалось, в нашей модели присутствует автокорреляция остатков. От автокорреляции можно избавиться, применив преобразование «Разность» к объясняемой переменной или воспользовавшись другим видом модели – моделью ARIMA или моделью ARMAX.
Возможные проблемы: Статистика Дарбина-Уотсона неприменима к моделям без константы, а также к моделям, которые в качестве факторов используют лагированные значения объясняемой переменной. В этих случаях статистика может показывать отсутствие автокорреляции при её наличии.
Модель линейной регрессии (метод инструментальных переменных)
Модель линейной регрессии с инструментальными переменными имеет вид:

где y – объясняемый ряд, x 1 , …, x k – объясняющие ряды, x ̃ 1 , …, x ̃ k – смоделированные при помощи инструментальных переменных объясняющие ряды, z 1 , …, z l – инструментальные переменные, e , ∈ j – вектора ошибок моделей, b 0 , b 1 , …, b k – коэффициенты модели, c 0 j , c 1 j , …, c lj – коэффициенты моделей для объясняющих рядов.
Схема, по которой следует проверять качество модели, является схожей, только к критериям качества добавляется J -статистика – аналог F -статистики, учитывающий инструментальные переменные.
Модель бинарного выбора
Объясняемой переменной в модели бинарного выбора является величина, принимающая только два значения – 0 или 1.
где y – объясняемый ряд, x 1 , …, x k – объясняющие ряды, e – вектор ошибок модели, b 0 , b 1 , …, b k – коэффициенты модели, F – неубывающая функция, возвращающая значения от 0 до 1.
Коэффициенты модели вычисляются методом, максимизирующим значение функции максимального правдоподобия. Для данной модели актуальными будут такие критерии качества, как:
- Коэффициент детерминации МакФаддена (McFadden R 2 ) – аналог обычного R 2 ;
- LR -статистика и её вероятность — аналог F -статистики;
- Сравнительные критерии: LogL , AIC , SC , HQ.
Нелинейная регрессия
Под моделью линейной регрессии будем понимать модель вида:
![]()
где y – объясняемый ряд, x 1 , …, x k – объясняющие ряды, e – вектор ошибок модели, b – вектор коэффициентов модели.
Коэффициенты модели вычисляются методом, минимизирующим значение суммы квадратов остатков. Для данной модели будут актуальны те же критерии, что и для линейной регрессии, кроме проверки матрицы корреляций. Отметим ещё, что F-статистика будет проверять, является ли значимой модель в целом по сравнению с моделью y = b 0 + e , даже если в исходной модели у функции f (x 1 , …, x k , b ) нет слагаемого, соответствующего константе.
Итоги
Подведём итоги и представим перечень проверяемых характеристик в виде таблицы:

Надеюсь, данная статья была полезной для читателей! В следующий раз мы поговорим о других видах моделей, а именно ARIMA, ARMAX.